



導入
本記事について
皆様は、Prompt Flowをご存知でしょうか。Prompt Flowとは、Microsoftが提供するLLM開発のためのOSSのツールです。Azure Machine LearningやAzure AI Studio上でも提供されており、それらをバックエンドとして動作させることができます。加えて、VS Code(Visual Studio Code)の拡張機能も提供されています。一方で、公式ドキュメント以外の情報が少なく、実際に活用するにあたって個人的にハードルを感じていました。
そこで本記事ではPrompt Flow(Azure AI Studio)を使用したRAGのアプリケーション開発の入門について、2回に分けてご紹介し、その簡易さや便利さを実感いただけたらと思います。なお、Azure AI Studioの一部機能はプレビューのため、プロダクトして活用する際は注意が必要ですが、PoC段階で低コストかつ迅速にRAG等のLLMを使用したアプリケーションを試したいシーンでは非常に有用だと考えております。
また、本記事が技術ブログへの初投稿のため、温かい目で見守っていただければ思います。Azureの公式ドキュメントの敷居を下げることを意識して執筆しましたので、本記事をきっかけにPrompt FlowやAzure AI Studioに少しでも興味を持っていただければ幸いです。
【第1回】
RAGの概要、On Your Data(Azure AI Studio)の概要/設定、Prompt Flow(Azure AI Studio)の概要/設定 等
【第2回】
Prompt Flow(Azure AI Studio)の推論エンドポイントのデプロイ、サンプルアプリのデプロイ/カスタマイズ、Azure AI Studioの評価機能、回答精度向上に向けた指針 等
注意事項
① 今回紹介する内容は記事執筆時点(2024/6/7)から更新されている可能性があるため、最新情報は公式ドキュメントのご確認をお願いいたします。
② 今回紹介する内容は一部プレビュー版の内容を含むため、運用環境では推奨されていない機能も含むことに注意してください。
③ ネットワークや認証等のセキュリティ設定については必要に応じて追加で対応をお願いいたします。
④ 本記事の内容に関連して発生するいかなる不利益、損害、またはその他の問題につきまして、一切の責任を負いかねます。読者の方々が本記事の情報を用いる際には、自己の責任において実施してください。
RAGの概要
RAGとは
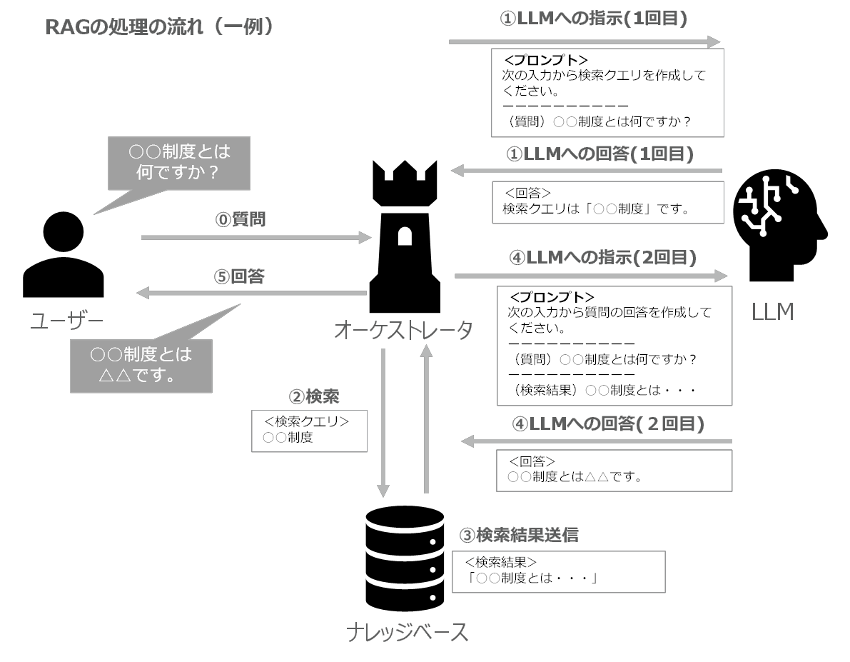
RAG(Retrieval-Augmented Generation)とは、事前に用意したナレッジベースのデータをLLMへの指示(プロンプト)に埋め込むことで、LLMが学習していないデータも加味して回答を生成することができるアーキテクチャです。下記のRAGの処理の流れの一例を示します。ここで、オーケストレータは、RAG全体の処理を定義し、ナレッジベースやLLMとを仲介する役割を果たします。
Azureで実装するRAG
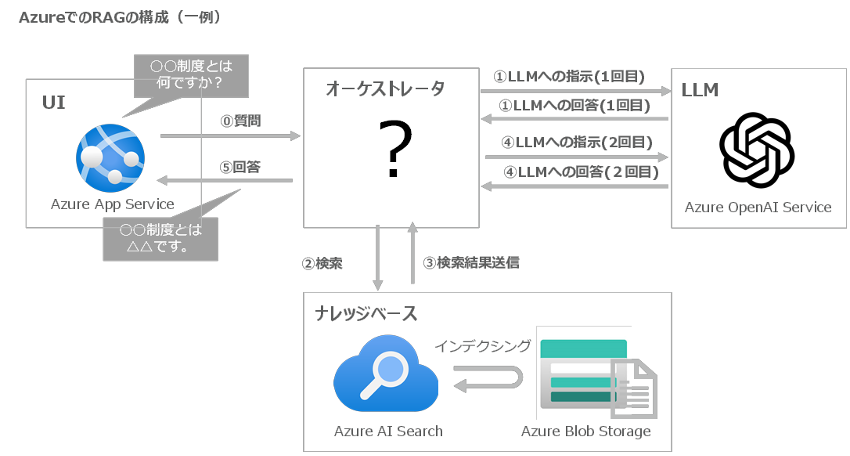
前述の通り、RAGの構成要素としては、大きく「LLM」「ナレッジベース」「オーケストレータ」があります。Azureでは、「LLM」に関しては「Azure OpenAI Service」、「ナレッジベース」に関しては「Azure AI Search」が基本的に選択され、「オーケストレータ」の実装方法でバリエーションが出てくると考えています。
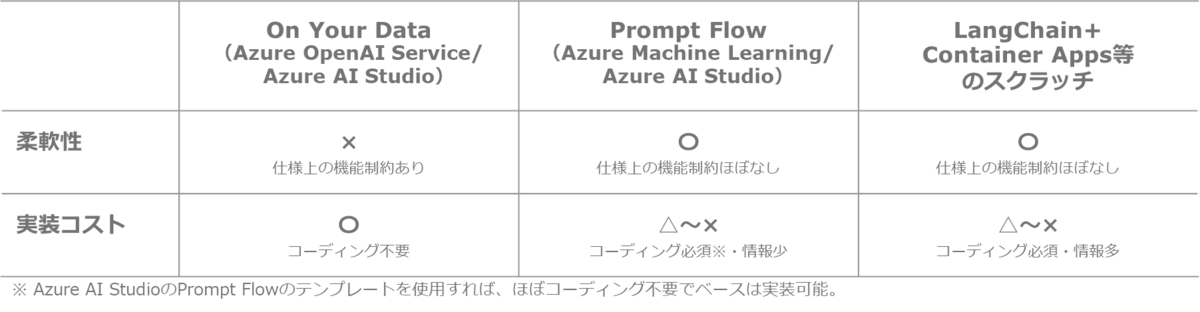
個人的な観点で、各オーケストレータの選定した場合の柔軟性・実装コストの比較表を整理いたしました。使用するオーケストレータにより、柔軟性と実装コストでトレードオフの関係にあると考えています。
実装
全体の流れ
以下の公式ドキュメントを参考にステップバイステップで実装していきます。
Azure AI Studio でプロンプト フローを使用して質疑応答コパイロットを作成してデプロイする - Azure AI Studio | Microsoft Learn
① On Your Dataの設定
まずAzure AI StudioのプレイグラウンドからOn Your Dataを設定します。
② Prompt Flowでのフロー作成
続いて、①にて設定したOn Your DataをPrompt Flowとして編集する機能を活用して、フローを作成します。
前提条件
以下の前提条件を満たすように準備をお願いいたします。
Azure AI Studio でプロンプト フローを使用して質疑応答コパイロットを作成してデプロイする - Azure AI Studio | Microsoft Learn
・Azure OpenAIへのアクセス権の申請が完了していること。
https://aka.ms/oai/access
・Azure AI Hub・Azure AI Projectが作成され、任意のChatモデル/ Embeddingモデルがデプロイされていること。
プロジェクトを作成して Azure AI Studio でチャット プレイグラウンドを使用する - Azure AI Studio | Microsoft Learn
なお、本記事では、Chatモデルは「gpt-4-1106-preview」、Embeddingモデルは「text-embedding-ada-002」を使用しています。
・ストレージアカウントがデプロイされ、新たに作成したコンテナにRAGで使用するドキュメントがアップロードされていること。
ストレージ アカウントを作成する - Azure Storage | Microsoft Learn
クイック スタート: BLOB のアップロード、ダウンロード、一覧表示 - Azure portal - Azure Storage | Microsoft Learn
なお、本記事で使用するドキュメントは、経済産業省が公開しているモデル就業規則(Wordファイル)です。
モデル就業規則について |厚生労働省 (mhlw.go.jp)
・Azure AI Search(Basicプラン以上)がデプロイされていること。
ポータルで Search サービスを作成する - Azure AI Search | Microsoft Learn
・デプロイしたAzure AI services(若しくはAzure OpenAI Service)、Azure AI Search及びストレージアカウントに接続されていること。
Azure AI Studio で新しい接続を追加する方法 - Azure AI Studio | Microsoft Learn
On Your Dataの設定
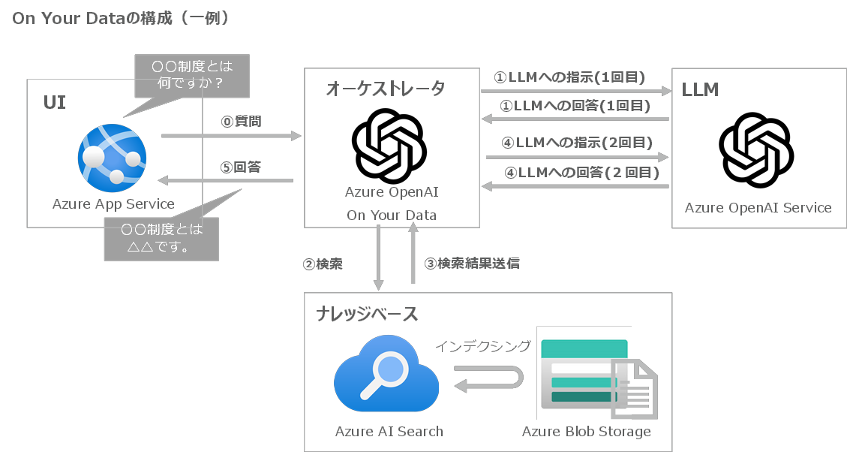
On Your Dataとは
On Your Dataとは、Azureが提供するRAGをノーコードで実装するPaaSサービスで、Azure OpenAI ServiceやAzure AI Studioのプレイグラウンドで提供されています。
Azure OpenAI Service で独自のデータを使用する - Azure OpenAI | Microsoft Learn
On Your Dataの構成イメージは下図の通りです。
On Your Dataの設定手順
今回は後続のPrompt Flowへの接続を見据えて、Azure AI StudioのプレイグラウンドからOn Your Dataを設定します。なお、前述の前提条件が満たされているものとし、Azure AI Studioのプレイグラウンドからの設定を説明します。
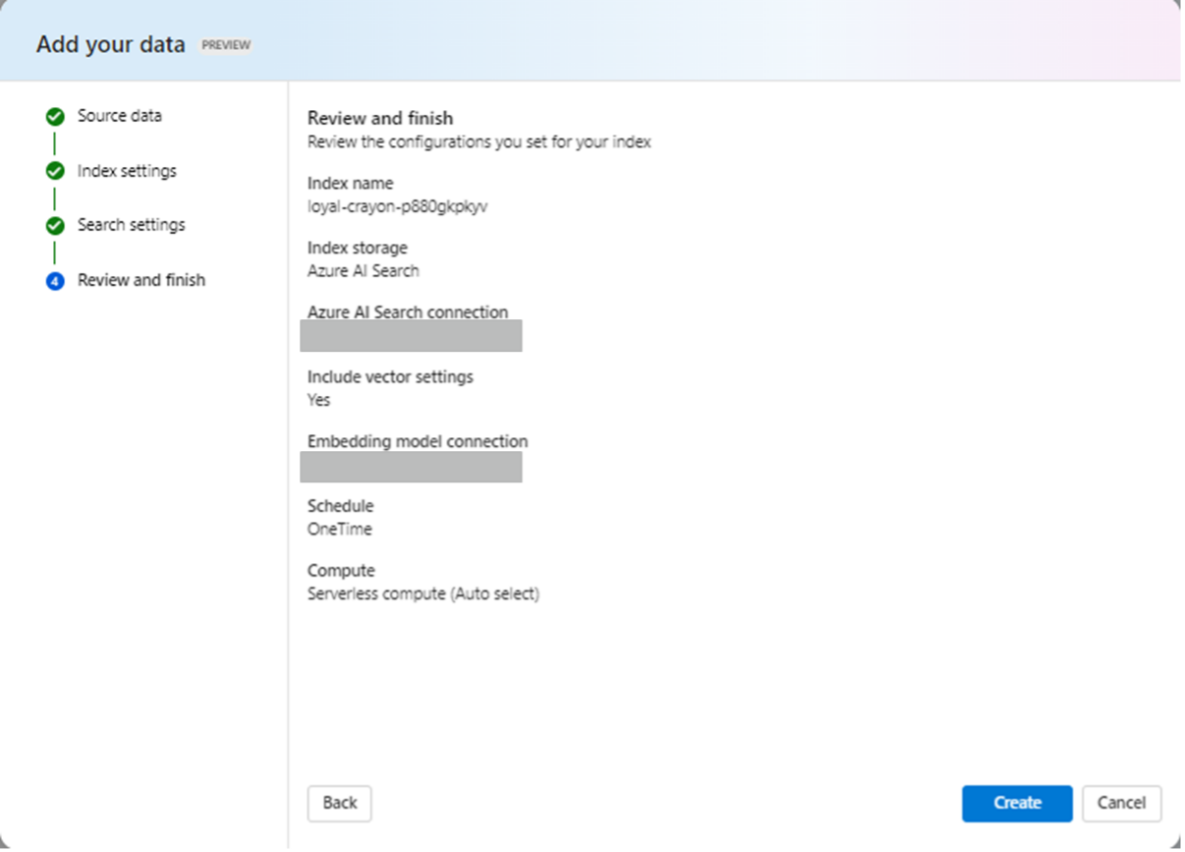
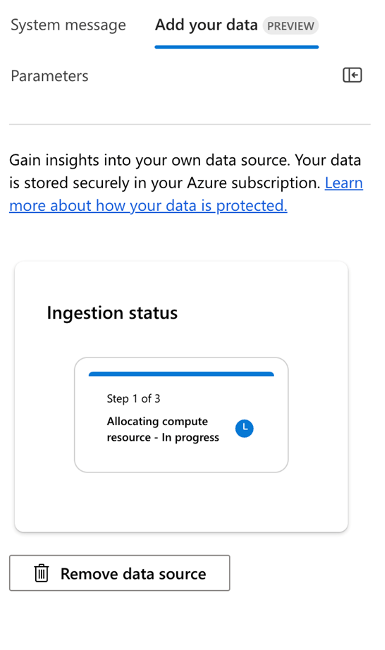
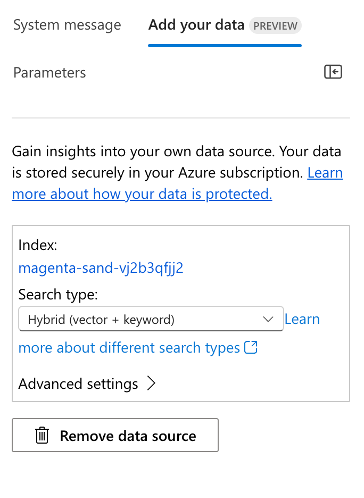
① Azure AI Studioの作成したProjectのプレイグラウンドにアクセスし、[セットアップ] ペインで、[Add your data]>[+Add a new data source] の順に選択します。
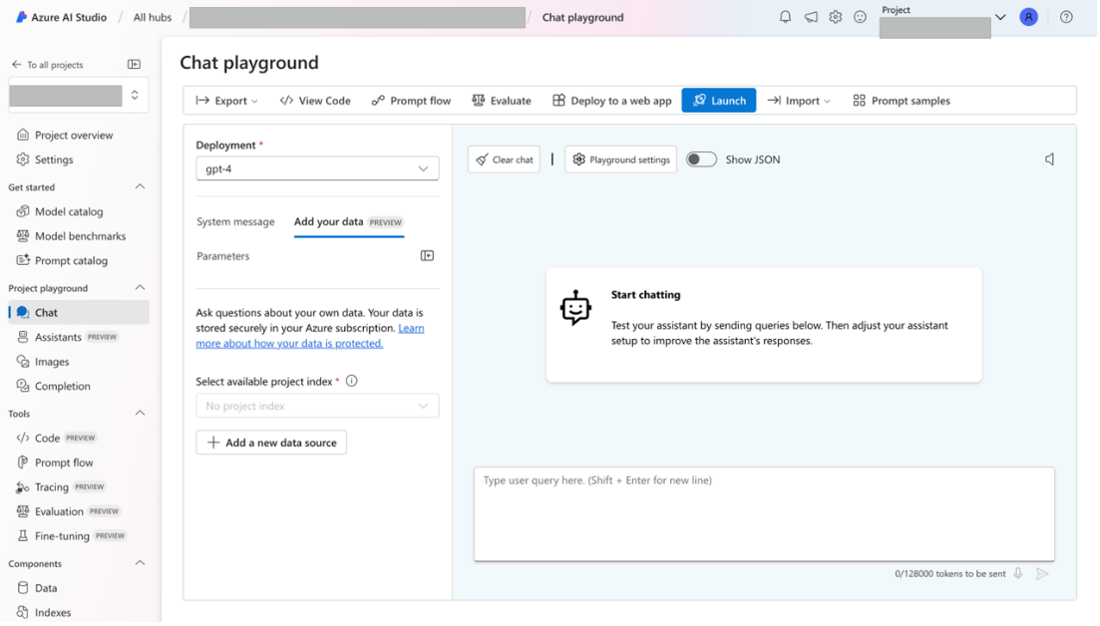 ② 添付画像の通り、設定を実施し、完了するまでしばらく待ちます。
② 添付画像の通り、設定を実施し、完了するまでしばらく待ちます。
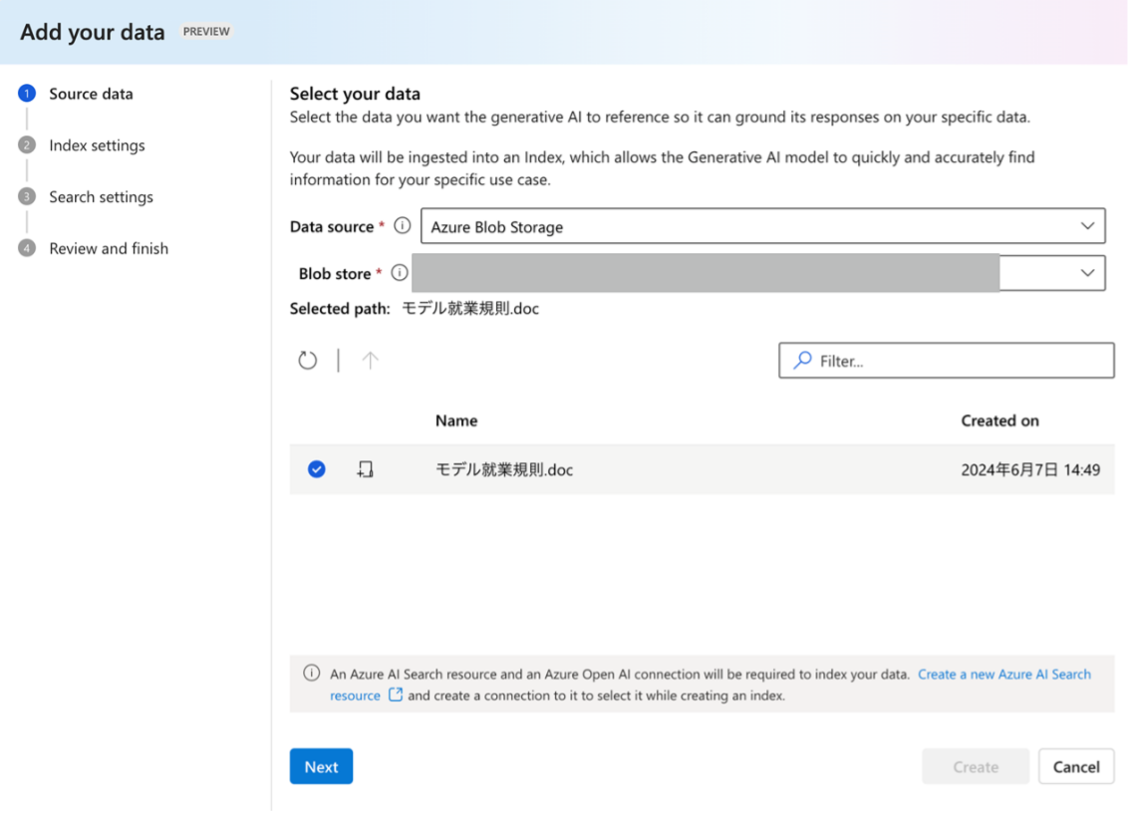
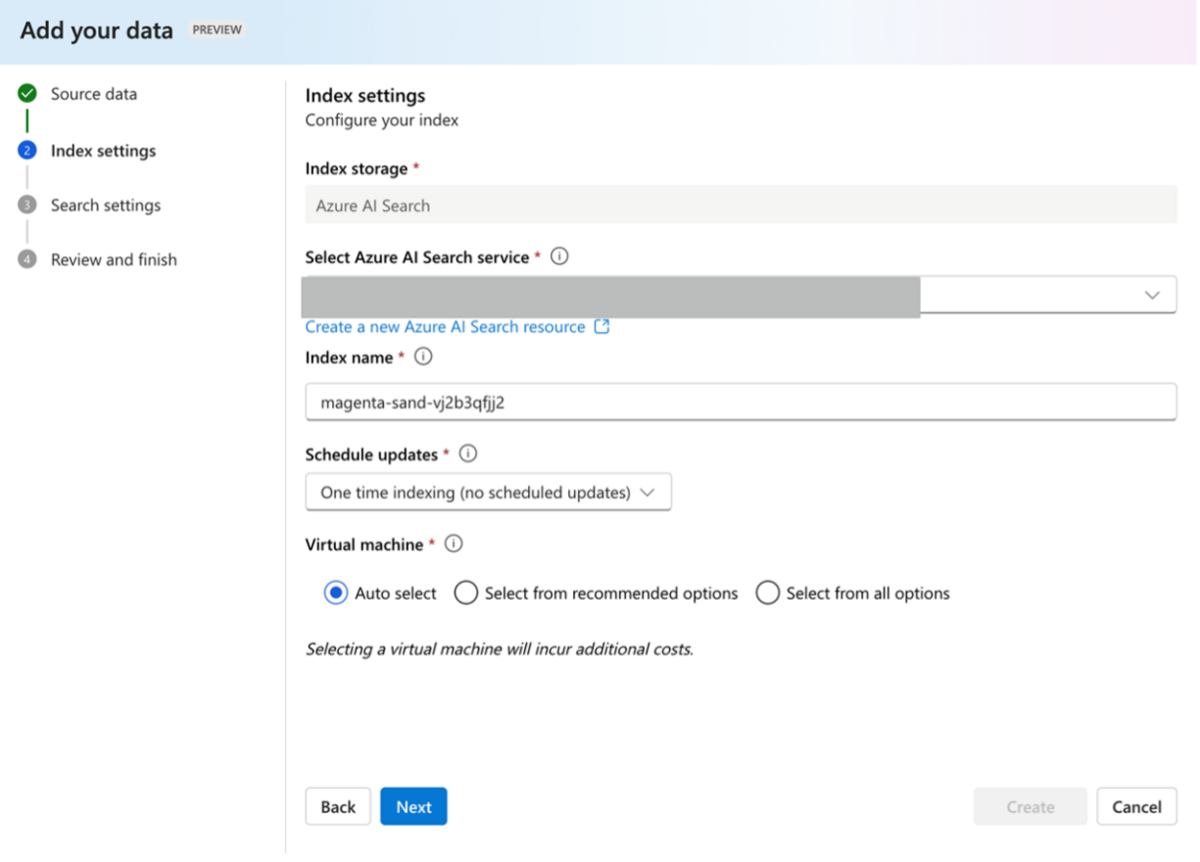
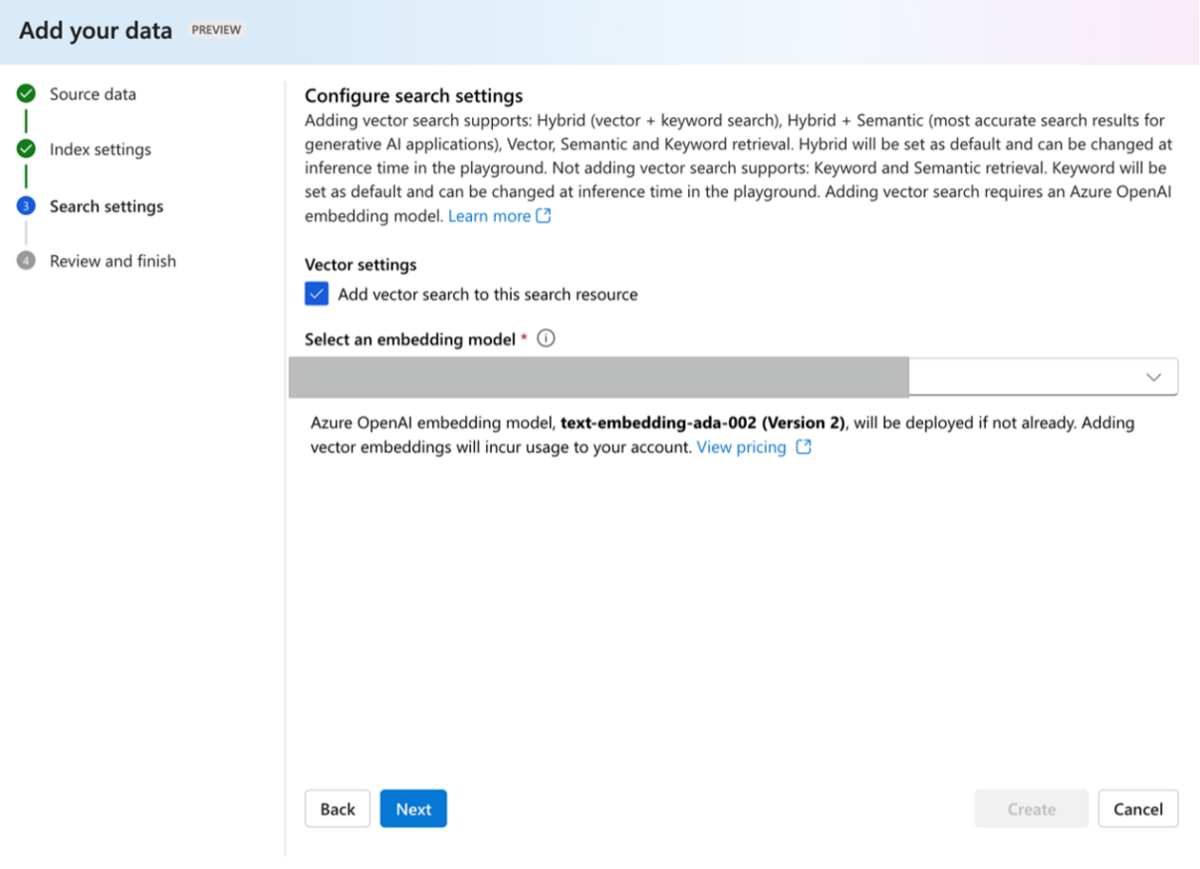
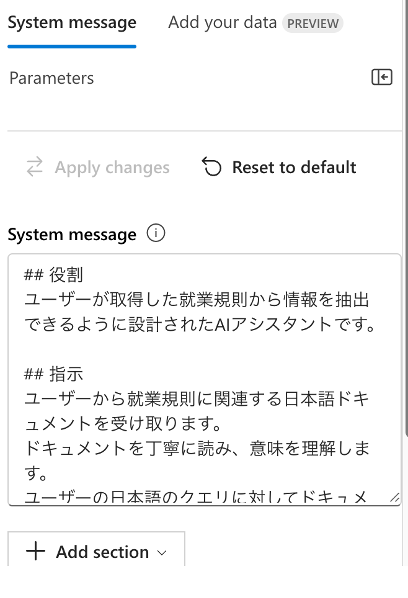
③ システムメッセージに以下のプロンプトを入力します。
## 役割
ユーザーが取得した就業規則から情報を抽出できるように設計されたAIアシスタントです。
## 指示
ユーザーから就業規則に関連する日本語ドキュメントを受け取ります。
ドキュメントを丁寧に読み、意味を理解します。
ユーザーの日本語のクエリに対してドキュメントの内容を元に日本語で回答します。
## 注意点
あくまでドキュメントのみを情報源とし、自身の知識は使用しません。
ドキュメントから答えられないクエリには、その理由を説明します。
④ 試しにチャットを投げてみると以下の回答が得られました。gpt3.5だと回答が返ってこなかったり、英語で返ってきたりすることがあります。
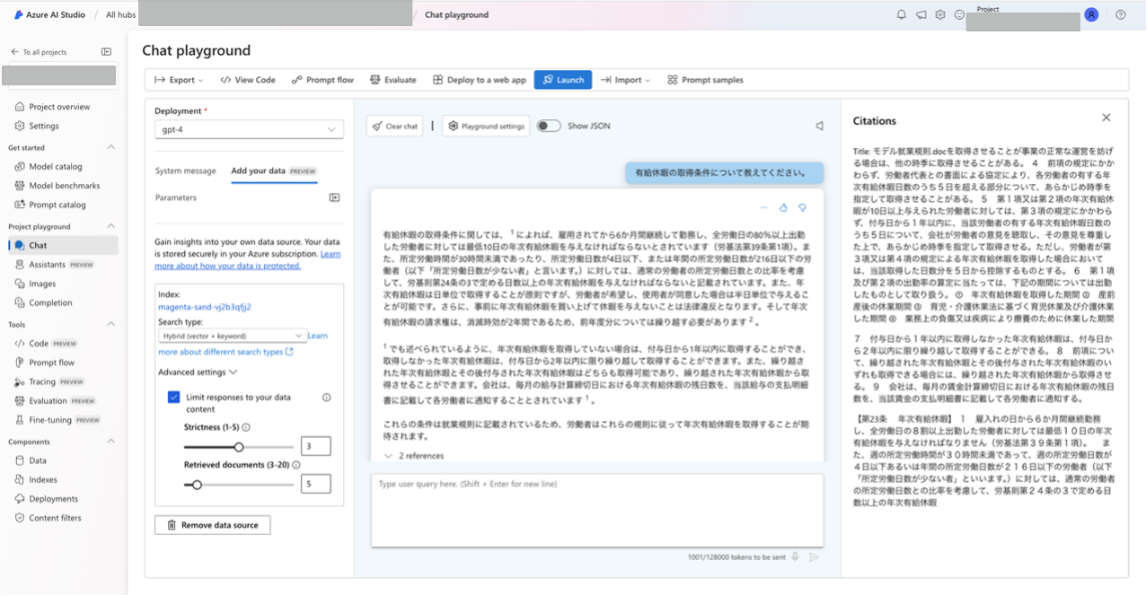
以上でOn Your Dataの設定が完了しました。お疲れ様でした。
On Your Dataの回答精度を向上させる方法
On Your Dataの回答精度を向上させる方法は下記公式ドキュメントに整理されています。
Azure OpenAI Service で独自のデータを使用する - Azure OpenAI | Microsoft Learn
On Your Dataでは回答精度向上に向けた試行錯誤に取り組む中で衝突する課題が大きく3つあると考えています。
① 検索クエリ生成と回答生成のChatモデルが分けることができない。(On Your Dataの内部の機構は公開されていませんが、検索クエリ生成にChatモデルを使用している可能性が高いと筆者は考えています。)
② 検索クエリ生成と回答生成のプロンプトがブラックボックスのため、プロンプトのチューニングできない。なお、回答生成のプロンプトはシステムメッセージから一部チューニング可能です。
③ RAGの全体のアーキテクチャがブラックボックスでチューニングができない。PoCとしてはOn Your Dataで十分という見方もできますが、これらの課題はもう一歩精度向上を図りたいときに大きな足かせになると感じています。特に自社のユースケースに特化させようとしたときに②は大きなボトルネックになり得ます。Prompt Flowではこれらの課題を解決することができます。
Prompt Flowでのフロー作成
Prompt Flowとは
Prompt Flowは、LLMアプリケーションを開発するためのOSSのツールで、開発サイクルを効率化するために、アイデア出し、プロトタイピング、テスト、評価、本番環境へのデプロイやモニタリングといった用途をサポートする機能があります。Azure Machine LearningやAzure AI Studioでも提供されており、それらをバックエンドとして動作させることが可能です。また、VS Codeの拡張機能も提供されています。
GitHub - microsoft/promptflow: Build high-quality LLM apps - from prototyping, testing to production deployment and monitoring.
筆者はLangChainやSemantic Kernel に近いサービスという印象を持っていましたが、以下の公式のQAにある通り、Microsoftとしては補完関係にあるサービスと位置付けているようです。
プロンプトフローはMicrosoftのLangChainに相当するものですか?
プロンプト フローは、LangChain と Semantic Kernel を補完するものであり、どちらとも併用できます。プロンプト フローは、評価、デプロイ、明確に定義された資産の監視、フロー ロジックを提供し、アプリケーションのデバッグや大規模なオーケストレーションのテストに役立ちます。
Azure AI Studio - 生成 AI 開発ハブ | Microsoft Azure
Prompt Flowのポイントを以下にまとめます。
・ Toolと呼ばれる処理を定義したノードを組み合わせてフローとして全体の処理を定義します。
・Toolは組み込みで「LLM」「Prmopt」「Python」等が存在します。また、組み込みのToolに適したものが存在しない場合は、カスタムのToolを作成することも可能です。
今回使用するToolの役割は下記の通りです。
・LLM:プロンプト及びLLMの設定を定義
Azure AI Studio 内のフロー用 LLM ツール - Azure AI Studio | Microsoft Learn
・Python:Pythonの処理を定義
Azure AI Studio 内のフロー用 Python ツール - Azure AI Studio | Microsoft Learn
・Index Lookup:ナレッジベースの検索処理を定義
Azure AI Studio 内のフロー用インデックス参照ツール - Azure AI Studio | Microsoft Learn
Prompt Flowの詳細は、以下の公式ドキュメントを参照してください。
Azure AI Studio でのプロンプト フロー - Azure AI Studio | Microsoft Learn
プロンプト フローのビルド方法 - Azure AI Studio | Microsoft Learn
Prompt Flowのフロー作成手順
On Your Dataの設定の続きになります。
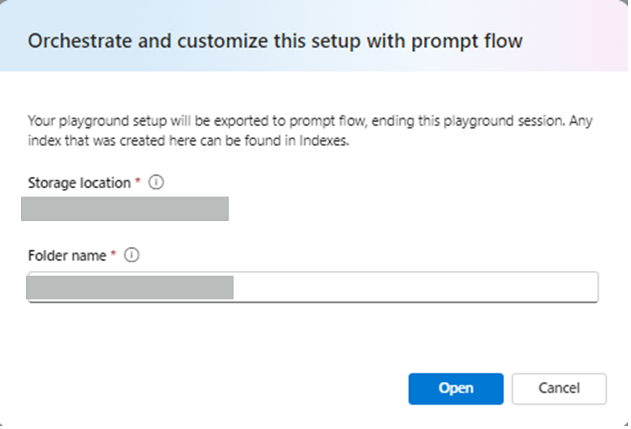
① [チャット セッション] ウィンドウの上にあるメニューから、[Prompt Flow] を選択し、添付画像の通り設定し、フローにアクセスします。
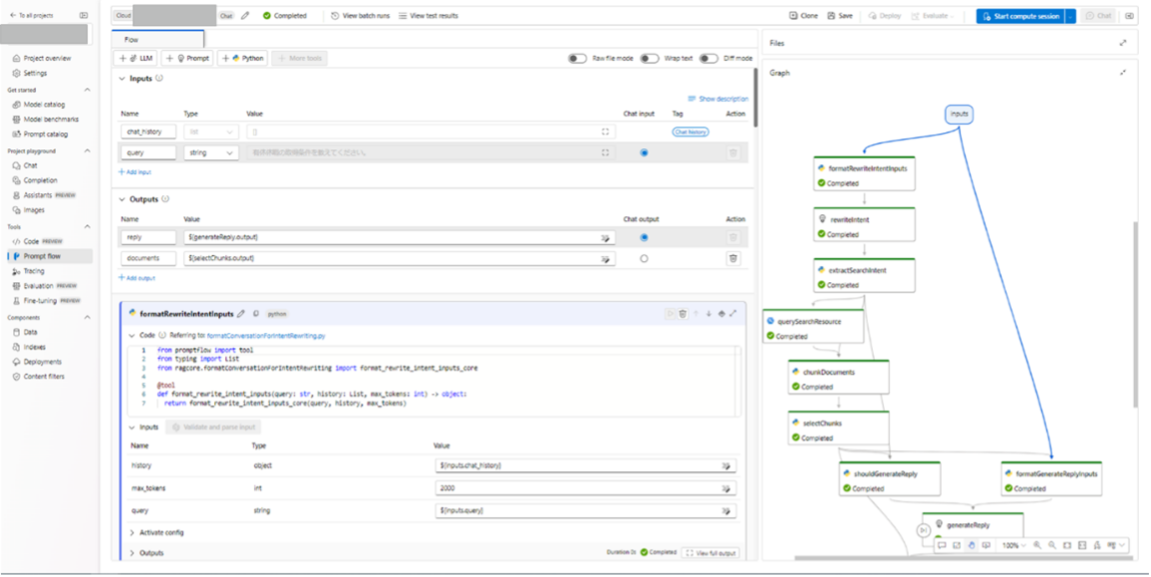
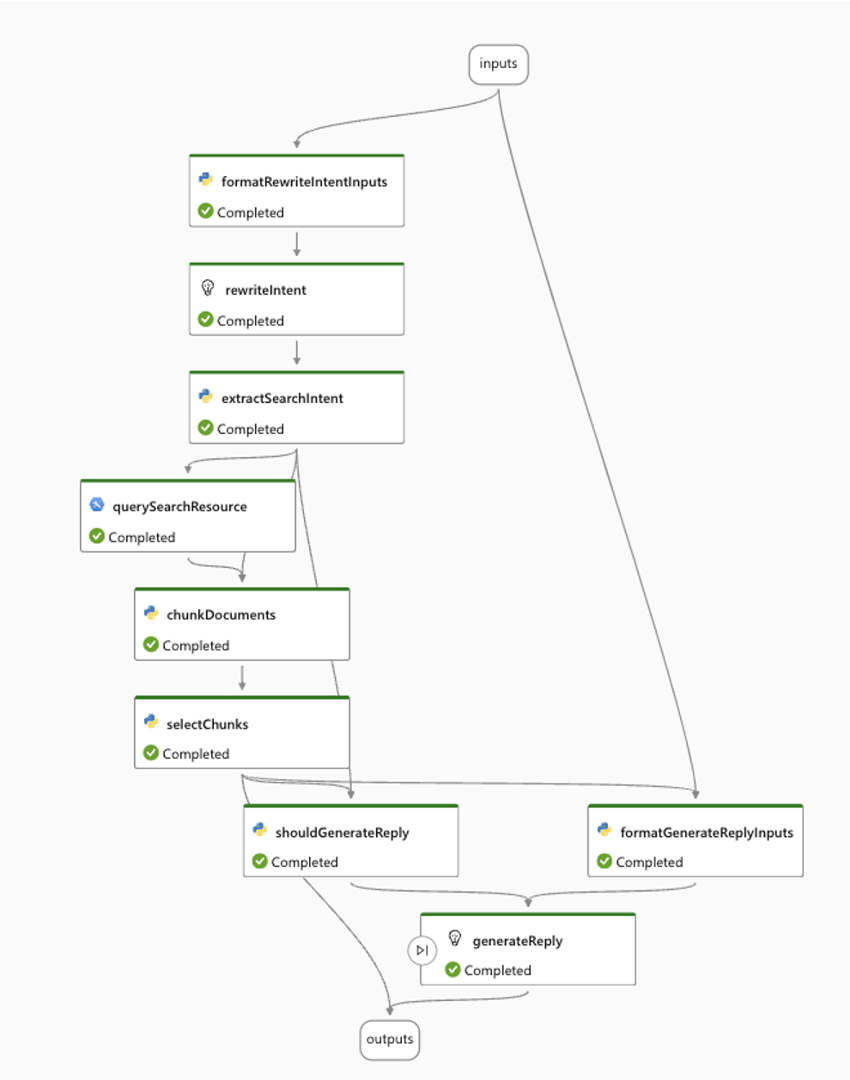
デフォルトで作成される各ノードの役割は以下の通りです。(記事執筆時点では公式ドキュメントが更新されていなかったため、想定を記載しています。)
formatRewriteIntentInputs(python):ユーザーからのクエリと会話履歴を取り、指定したトークンの最大数に基づいて整形するためのする処理
rewriteIntent(LLM):ユーザーのクエリの意図を判断し、検索クエリを生成するためのプロンプトを定義
extractSearchIntent(python):rewriteIntentノードの出力の書式を設定するためのプログラム(文字列を引数として受け取り、その文字列に含まれる「意図」をリストとして返す)
querySearchResource(Index Lookup):Azure AI Search等のナレッジベースから検索を行うツール
chunkDocuments(python):検索結果として得られたドキュメントのリストをチャンク(区切り)に分割するプログラム
selectChunks(python):チャンクを選択し、スコアに基づいてフィルタリングして返すプログラム
shouldGenerateReply(python):条件に基づいて返信を生成すべきかどうかを判断するためのプログラム
formatGenerateReplyInputs(python):selectChunksノード及びinputsの出力の書式を設定するためのプログラム(与えられたクエリ、会話履歴、文書のチャンク、およびトークンの最大数に基づいて、応答を生成するための入力をフォーマットする)
generateReply(LLM):取得したドキュメントを使用して応答するためのプロンプトを定義
② [Start compute session]をクリックし、コンピューティングセッションを開始します。
③ [Chat]を選択し、フローが正しく機能するかテストします。Azure AI Studioの言語設定が日本語になっている場合、フローの設定値が翻訳されて上手く動作しない場合があります。その際は該当箇所を修正してください。
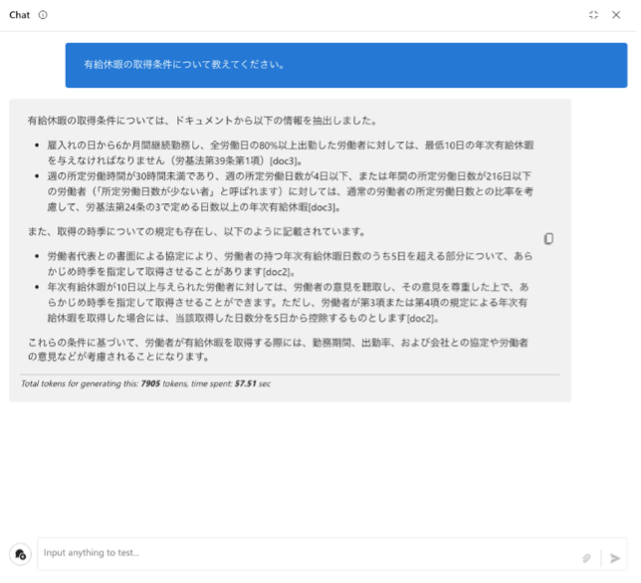
以上でPrompt Flowの基本設定が完了しました。お疲れ様でした。コストが発生し続けてしまうため、必要に応じてコンピューティングの停止やリソースの削除を実施してください。
お気づきの通り、プロンプトフローでは、各ノード単位で詳細な設定が可能であるため、On Your Dataの課題が解決可能です。各プロンプトの改善にあたっては、プロンプトフローの評価機能を駆使しながらデフォルトのものをベースに追記・編集する形が良いと思います。
最後に
本記事では、Azureが提供するLLMプロダクトを開発するサービスである「Prompt Flow」(及び「On Your Data」)を紹介しました。本記事で紹介させていただいた内容で、Azure AI StudioでPrompt Flowを使用したRAGを簡単に実装できることを体感いただけたのではないかと思います。
第2回では、Azure AI Studioのサンプルアプリや評価機能といったもう一歩踏み込んだ内容をご紹介できればと思います。
本記事の内容が少しでもRAGの導入やPrompt Flowの活用にお役に立てていただけましたら幸いです。
記事執筆者

雨谷 健司
パーソルキャリア株式会社
デジタルテクノロジー統括部 デジタルビジネス部 アナリティクスグループ
前職は鉄道会社で駅係員をはじめとした現業研修後にテクノロジー部門で社内DXの推進やデータ利活用組織の基盤作りに従事。パーソルキャリア入社後はアナリストとして、データ分析、機械学習モデルの開発、施策設計・評価、データマネジメント、生成系AIに関連するアプリケーション開発/検証に携わっている。

