


こんにちは!TECH Street編集部です!
今回は2021年1月28日(木)に開催した、 【データ分析基盤エンジニアTalk ~運用・自動化そして活用~】のイベントレポートお届けいたします!
事業会社のデータ分析基盤開発に携わるエンジニアが集結し、基盤開発における運用自動化TIPS、活用される分析基盤や構築事例、工夫などなどを語っていただきました♪
今回の登壇者の方はこちら◎
・鈴木 裕之さん/パーソルキャリア株式会社
・塩崎 健弘さん/株式会社ZOZOテクノロジーズ
・平野 雅也さん/Retty株式会社
※登壇順
さっそく、ご紹介していきます!
「AWS のマネージドサービスを活用したデータレイクと分析基盤の環境改善」(鈴木 裕之/パーソルキャリア株式会社)
データ分析基盤の導入期と課題
様々なサービスが展開されるたびに運営に必要な分析業務もサービスごとに展開されていた状況下で、様々な課題が出てきてしまったと話す鈴木さん。
安全な環境をつくるためにデータ分析基盤の導入を検討し始めたそうです。データ活用においては以下の3つのポイントをビジョンとし、プロジェクトを開始しました。
①ビジネスとして実務に利用するべく環境が整っていること
②データサイエンスの活用サイクルが運営できていること
(モニタリング、課題定義、データ探索予測モデル、施策展開)
③管理体制をおき、セキュリティ管理が徹底され安全に利用できる環境になっていること
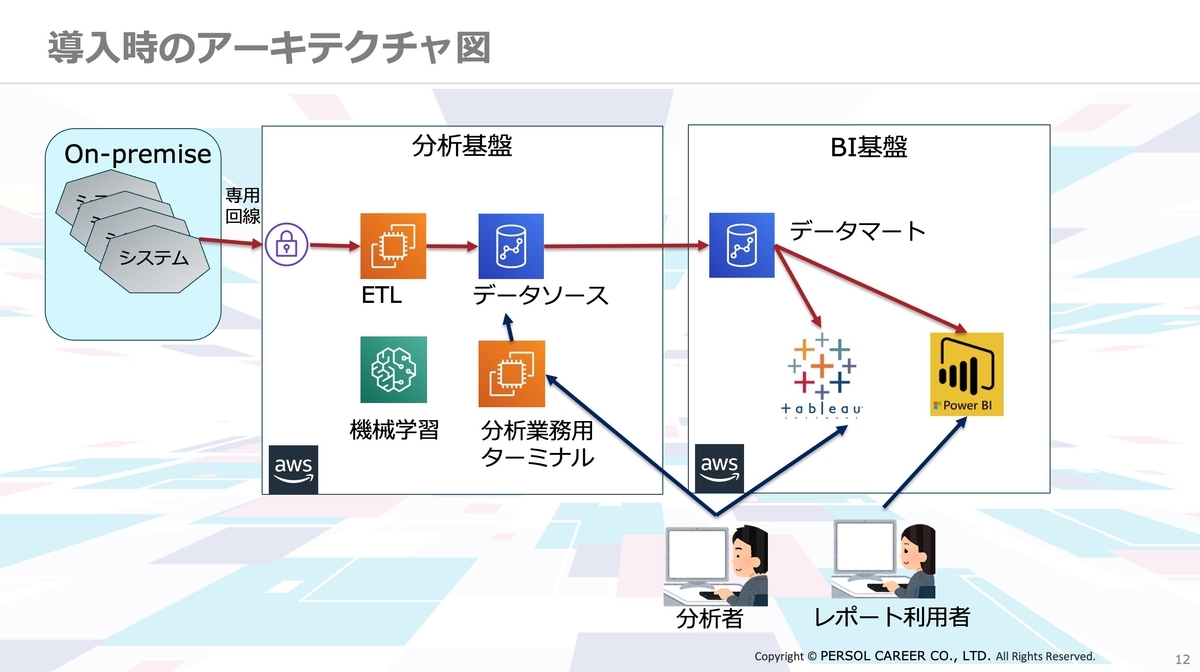
導入時のアーキテクチャはシンプルなもの。データベースで構築しており、Redshiftにデータを蓄積していくような形を取っていたそうです。
データ活用には主に4つのカテゴリーがありました。
・BI活用:売上貢献、サービス向上、あらゆる部署でのデータ利用
・AI活用:テキストマイニングや営業予測の利用
・CRM活用:メールマガジンやレコメンド機能への利用
・システム活用:パーソルキャリアが展開する様々なサービス
しかし、運営を始めてから直面した課題が…!
運営開始後の課題
使っていくうちにどんどんデータがどんどん増えてゆき、ボリュームが枯渇。その中でもどんどんスケールアウトして行かなければならず、夜間バッチは増え、異常終了も多発。手運用で行っている業務も多数ある中、利用者からの問い合わせ件数も急増…!
このような状況を打破するべく、2つの取り組みを実施したそうです。
①安定稼働のためのシステム強化
まずはインシデントの発生を減らし、システムを強化するためにデータレイクを作ることに。データボリュームの増加は半年で1.4倍にもなっていたのだとか…!スケールアウトしていくと、Redshiftのコストもかかるため、データレイクとして構築することを想定。

分析者はデータ領域に入ったRAWデータの参照をする際、Spectrumを経由することで簡単にSQLで操作していたものを変えずに実現することができます。Redshiftの成長をここで抑制させ、これまで捨てることもあった古い過去のデータは永続的にアーカイブ、Glaciarに転送するような仕組みを導入したのだとか。
次に、老朽化したバッチの改善について。
一つ一つのデータボリュームが終わったら次の処理へ映るような仕組みを構築しようとしましたが、データソースが800テーブル以上、マート処理が数千テーブルというような規模で、かつ毎週20コマとか増えてくような状況の中で1個1個ネットを組み、スケジューラーを組むという方法では管理しきることは現実的ではなかったのだとか。

そのため、今回はQUEを使い、データ自体が集まったら、マートが使っているテーブルを管理し、マートが作るジョブの中でデータソースが揃ったら次に動くというような仕組みを導入したそうです。
データソースのLOADに関しても、プロセスを複数起動させて並列に稼働させることで処理効率を上げるというような取り組みもしているのだとか。こちらにより、今まで0時からサービス開始の10時までに間に合わなかったような処理が、10%改善したのだとか…!◎
②管理機能の強化
運用業務ではアカウント発行やプライバシーデータのセキュリティチェック、問い合わせ対応などを、そして保守業務ではシステムの稼働管理、マートジョブ開発、システム間連携の開発などを対応しているのだとか。
保守運用業務といっても開発やユーザーからの問い合わせ対応など、様々な業務が発生。これらの管理のため、ジョブ管理ではA-AUTO、システム管理ではMcAfeeやZabbixを導入し、足固めを進めてきたそうです。この中の、異常検知システムである電話通知について、説明していきます。
ここで登場するのがAmazon Connect。
Amazon Connectを使った保守検知
・できるだけ、人を介さずシステム化したい。
・できるだけ、保守メンバーに気付かせたい。
・できるだけ、マネージド、サーバーレスで自分たちで作りたい。
このようなことを実現するため、着目したのがAmazon Connectの電話をかける機能や自動音声の機能だったのだとか。
・エラーメッセージを読み上げること。
・電話に出なかったら次の担当者に架電。
・一巡しても応答ない場合、先頭から担当者に架電。
そもそも、Amazon Connectはコールセンターの電話窓口のためのマネージドサービスなんだとか。例えば、宅配の再配達で電話をかけた際の自動音声サービスで使用されています。入力した番号によって自動音声メッセージが流れ、電話をかけるというAPIもあるそうですが、電話に出たかどうかがわからないという仕様だったため、制御は自分たちで作ることとしたそうです。

まず、電話番号をマスターのAmazon DynamoDBに登録。エラー自体はZabbixで検知させ、検知したものがS3にログを吐き、それをQUEにため、AWS Lambdaが検知してマスターDynamoDBから電話番号を取得。架電のQUEに入り、実行ファンクションがAmazon Connectに電話させるという流れです。
架電した際、ユーザーが何かボタンを押したか否か、というアクションを取ることができるので、ボタンを押した=電話に出た、と判断するようにしたそうです。
次にテキストの読み上げについて。

テキストの読み上げはAmazon Pollyという機能を使います。自動的にメッセージを読み上げることができますが、イントネーションを変えたり、ワンテンポ置いたりというような設定ができるのだとか。(アレクサなどでも使われているそうですよ!)
通常の保守検知サービスを契約した場合は、1Nodeあたり約月7000円程度かかってしまうそうですが、実際に12月に使ったAmazon Connectの請求はなんと415円!かなりの低コストで、管理機能の強化が実現できています◎
まとめ

▼データレイクの用意によって実現したこと
・データベースの容量抑制
・データベースの負荷分散
・プライバシーデータ管理の簡易化
・処理効率の改善
・ジョブ管理で優先度のコントロールが可能
▼Amazon ConnectやZabbixの導入によって実現したことも◎
・タイムリーに保守連絡が可能
・アカウント管理画面の作成で手運用をなくす
・ユーザー権限の運用工数軽減
また、今後はBI基盤の利便性の改善やプライバシーデータ管理強化、マルチクラウド化にも対応予定とのことです!今後もどんどん改善が進みそうで楽しみですね♪
データ分析から、業務改善、コスト削減まで、役立つ事例のご共有ありがとうございました!皆様もぜひ、こちらを参考に取り組んでみてください◎
続きまして、ZOZOテクノロジーズの塩崎さんにお話いただきました!
「Amazon AuroraのデータをリアルタイムにGoogle BigQueryに連携してみた」(塩崎 健弘/株式会社ZOZOテクノロジーズ)
ZOZOのAI活用事例

まず一つ目に、ZOZOTOWNでお買い物をした際に、「あなたにおすすめ順」で並び変えることができる機能。新着商品に対する感度や、セール商品に対する感度をユーザーごとに計算し、特徴量を商品情報と組み合わせることで検索結果をパーソナライズする機能です。(これはめちゃくちゃ便利ですよね◎筆者もよく使います)
次に、おすすめアイテムの表示機能。こちらはRecommendations AI(GCP)とZOZO研究所独自開発のAIのロジックを競わせており、ユーザーごとにおすすめの商品を推薦してくれる機能です。
AI案件が成功すると起こること
AI案件が成功すると、より高度なAIを開発したくなり、データ品質を上げる必要が出てきます。ここでいうデータ品質とは下記のような性質を指します。
・正当性・妥当性・有効性:意図に合う内容のデータか
・完全性:欠損のないデータか
・一貫性:データ間の関係に矛盾がないか
・適時性:最新のデータか
・適切な参照権限が付与されたデータか
(参照:ゆずたそ、はせりょ 『データマネジメントが30分でわかる本』より)
今回は、この中でも適時性にフォーカスして行きます。
大抵のデータ基盤では1日1回〜数回のバッチでデータを同期しており、日次・月次のレポート作成ではこの頻度で十分です。しかし、AIを活用しようとすると、1日1回では遅すぎることもあるのだとか…!AIの場合は、可能な限りリアルタイムのデータがデータ基盤に欲しいそうですが、リアルタイム連携は難易度が高く、必要性が不明なまま作ると大変。
とはいえリアルタイム連携を作ってみたのだとか。
・SQL ServerのChange Tracking機能(CDC的な機能)を活用
・Fluentd→Cloud Pub/Sub→Cloud Dataflow→BigQuery
・遅延時間:平均数十秒
十分にリアルタイムといっても問題ない程度のスピードが出ているデータ連携システムが出来上がりました。しかし、同時に課題も。
運用課題
・連携対象テーブルの追加・スキーマ変更の時にオペレーションが必要
・Cloud Dataflowのコードはちょっと癖がある
・大量のデータ更新があった時にCloud Dataflowのスケールが間に合わない
・Fluentdの冗長化に気をつける必要がある
これらの課題に対し、DWHからRDBのデータを直接参照できれば楽なのでは、と気づいたそうです。

RedshiftとBigQueryにはFederation機能があります。この機能を使うと、RedshiftであればRDSからのテーブルを参照できたり、BigQueryでは、Cloud SQLのテーブルに対してクエリを実行できたりするそうです。
マルチクラウドでこのような機能があればよかったのですが、さすがになく…今回のケースではAmazon AuroraからGoogle BigQueryにデータ連携をしたかったため、下記の作戦をたてたそうです。
・Amazon Aurora→Cloud SQL→BigQuery
・Cloud SQLはGCP外部のデータベースをプライマリとしてレプリカを作れる
・レプリを設定するためにネットワークの理解が必要不可欠
まず、Amazon Auroraのデータを一旦Cloud SQLにレプリケーションします。これによってCloud SQLとBigQueryは同一のクラウドにあるので簡単にFederationできます。

こちらがAWSとGCPのネットワークの概略図です。AWSはDBインスタンスが自分たちのVPCの中に置かれている一方、GCPのDBインスタンスは自分たちのVPCの外側にあるGoogleが管理しているVPC内に置かれています。そのためGoogle管理のVPCと自分たちのVPCの間がピアリングされていて、Amazon AuroraのVPCとCloud SQLのVPCが直接繋がっているわけではないという状態です。
VPCが直接繋がっていないとネットワーク的に問題があるのだとか。

そのため、この経路情報をうまく伝搬するように、真ん中のVPCに設定を入れる必要があります。VPCピアリングのexport custom routesという機能をオンにすると、AWSのVPCのCIDRがCloud SQLのVPCに広告されます。また、クラウドルーターの方でCustom route advertisementsという機能を使って、Googleの管理するVPC、つまりCloud SQLのVPCのCIDRを広告します。ここまで対応すれば、経路情報がうまく伝わるようになるそうです。
他にもプライマリインスタンスのホスト名60文字制限についてはAmazon Route 53に短いホスト名をCNAMEで登録して解決したり、GTIDなしのダンプデータはロードに失敗するので、レプリケーション開始時にプライマリDBから取得したダンプデータを用意して対応するなどの工夫をしたそうです。
あとはConnectorを作ればFederationが結構簡単にできるようになるそう…!Cloud SQLがBigQueryと同一のリージョンであり、External IPを付与されていればConnectorを作ることができるとのこと。
運用上の注意点
・EXTERNAL_QUERYは毎回クエリをCloud SQLで実行するため重いクエリには不向き。実行計画を確認しよう。
・何回も参照するテーブルはWorkflowの先頭でキャッシュする。BigQueryのテーブルに変換すればスピードアップするものの、リアルタイム性と実行速度のトレードオフとなる。
・High Availability構成について
・Cloud SQLが機能しなくなった場合、mysqldumpでAmazon Auroraからダンプを取得する必要があり、データ量次第では復旧時間が数時間になることもある。
・異なるゾーンにHot Standbyを用意する必要。
まとめ
・AI案件が成功すると1日1回のバッチでのデータ連携では遅くなる
・リアルタイム連携基盤の運用を楽にするためには工夫が必要
・マルチクラウドでは素直にFederationできないのでネットワーク周りの設定が肝
普段使っているZOZOTOWNの裏側ではこのようなデータ基盤が動いているのですね…!参加者の皆さまも興味津々でした◎塩崎さん、貴重なお話ありがとうございました!
「データの民主化と情報管理の取り組み」(平野 雅也/Retty株式会社)
自分にとってベストなお店が見つかる、日本最大級の“実名型”グルメサービスRetty。自分の好みや思想に近い人の口コミから、ベストなお店を見つけられるSNS型のグルメサービスです。
Retty分析チームは3つのミッションを掲げて業務に取り組んでいるそうです。
・意思決定の最大化
事業における意思決定の質とスピードをデータ分析を用いて最大化すること。
・基盤仕組みづくり
データ活用のための仕組みや基盤を開発/運用すること。
・データの民主化
組織全体がデータを使いこなせる状態を作ること。

現在のデータ分析基盤は上記のようなイメージ。転送システムとDWHのシステムに領域を分けていて、アプリケーションからFluentd、Kinesis、S3を経由し、そこからエアフロー上のジョブからBigQueryにいれ、BigQueryからBIツールに接続するという構成です。
現在はこの構成ですが、この構成に至るまで様々な紆余曲折があったのだとか…!

その後プロジェクトを開始する際、「データ分析基盤は社内メンバーをユーザーとしたプロダクト」という位置付けと整理し、プロジェクトを進めていく上の指針としたそうです。
具体的には、プロダクト改善とチーム改善に取り組んだそうです。
プロダクト改善
データ分析基盤にもUser Happyを求める、という指針。
User HappyはRettyの行動規範の一つなんだとか。あらゆる判断で迷った時にUserがHappyであることを優先して判断するようにしているそうです。ここでいうUserとはRettyの利用者や飲食店を指していましたが、この考え方をデータ分析基盤にも活かしたそうです。
①ユーザーを知る
データの民主化が進んだことにより全社的にユーザーがいるためユースケースも様々。また、データ分析基盤についての質問や日々なんとなく感じている不満を拾い上げて少しずつ解決することを意識したそうです。特に、データアナリストが感じる不満はツールに馴染んでも感じる可能性があるので注意したそうです。
②ユーザーと作る
全社的なデータマネジメントの課題解決は原則的にデータアナリストと協働した方が良いと考えているそうです。というのも、データエンジニアだけで考えた解決策は多くの場合ユーザーにとって「守りすぎ」になりがちと考えているからだそう。データ分析基盤のユーザーに制限を強いるのではなく、理想へ少しずつ優しく誘導していくことを意識しました。
チーム改善
Retty開発チームの知見を生かしてチームを管理することに取り組んだそうです。
①チーム運営にスクラムのエッセンスを取り入れる
プロダクト側でスクラム導入を進めているプロフェッショナルにKPTに参加してもらい、個人のスキルやモチベーションに依存したタスク管理からの脱却を目指したそう。まずは計測し、己を知ることから始めたのだとか。チーム協働のプランニングを経ることで、ドメイン知識やタスク分析能力の偏りを補い合えるような体制を整えたそうです。
②チームを超えて組織的に知見を広げる

例えば、キャッチアップした際に得た情報を積極的に発信するなど、個人の努力をチームに還元することを意識したそうです。データ分析は全社的なものなので、他チームの開発者も関心を持ってくれ易かったのだとか。日頃から、情報発信をすることで、チームを超えた横断的な技術改善のための必要なコミュニケーションに繋がる体制を構築したそうです。
まとめ
半年間の取り組みを経た気づきや、取り組みの結果は以下の通り。
・プロダクト改善:データ基盤にもUserHappyを求める
全社的に広がるデータ分析基盤のユーザーに対して、継続的に課題把握と改善施策を実施。データアナリストと協働するとより中立的で現場メンバーの管理意識が芽生えやすい方針が建ちやすい。
・チーム改善:Retty開発チームの知見を生かしてチーム管理をする
スキルとドメイン知見の偏りを是正する習慣がつき、技術外観が伺えるドキュメントは十分な状態へ。データ分析基盤チーム以外の開発メンバーとも、共通項を見出して議論ができる民主化され始めた状態に。
チームだけでなく全社を巻き込んでナレッジを共有し、データ分析基盤をより強固なものとしていくRettyさんの取り組みでした◎
まとめ
3社の発表はいかがでしたか?実際に運営している方々からの実例紹介と解決策を細かく教えていただき、貴重な機会になったのではないかと思います!
参加者からの声
・実際に運用されているデータ分析基盤についてシステム構成含めて詳細なお話しを聞けたこと。
・皆さん実務に基づいた濃い話で良かった
・分析基盤エンジニアの生の声が聞けてよかった
・こんなことまで勉強会で教えてくれるなんて!と思うほどお三方の発表は知見でした。ありがとうございました。
・ありがとうございました!動画公開してほしいほどです。こういったラフに色んな会社の知見が学べる会は良い
ビデオオンの参加者の方々との集合写真

次のページでは、参加者の皆様から頂いた質問についてもご紹介いたします♪
参加者からの質問
鈴木さんへの質問
(Q1)人材紹介=個人情報が過多に含まれるのでどうやって『分析』するのでしょうか。マスクする/しない はどのような基準で判断されていますか?
(A)扱っている個人情報にもパターンがありますが、社内で取り扱いのルールが決まっています。
(Q2)ETLツールって結構重要ですよね?こだわりました?(なにつかっていますか?)
(A)Talendは使っています。今回は、スレッドをちゃんと使いたかったので手組みしました。
(Q3)パーソルさんの分析基盤系のエンジニアは何名くらいなんでしょうか?
(A)正社員12名、パートナー12名のチームです。
(Q4)TableauさんとPower BIの使い分けのポイントは?
(A)そこまで大きくないですが、利用者が多い場合はPower BIを使っており、ニッチなものやマーケの方が使うものはTableauを使っています。
(Q5)登壇社全員に聞いてみたい データ分析の一番の失敗談(ビジネス系でもテック系でも)
(A)前職でGreenplumというデータベースを使っていたとき、トランザクションIDが枯渇してしまい、データベースが停止してしまったことがあります。その際には2日間寝ずに復旧作業をしたことがあります。
(Q6)データ分析基盤って、収集、蓄積、活用、どの段階が一番難しいというかキモになりますかね?
(A)どこも難しいですが活用がポイントだと思います。どういうデータでどのサービスで効果が出たかまで持っていくのが難しいと思います。
塩崎さんへの質問
(Q1)塩崎さん、これまでにきた依頼で一番難易度が高かったものはどんな内容でしたか?
(A)今回紹介したリアルタイム連携が最も難易度が高かったです。
(Q2)CDCってなんですか?
(A)テーブルに対してUPDATEとかINSERTなどの更新系の処理をかけた時に、更新のあった行だけをピンポイントにSELECTできる機能です。
(Q3)リアルタイムデータどこもニーズありますよね。ユーザ側うまく活用できていますか?
(A)リアルタイムデータは検索した後の検索順を「おすすめ順」表示する際Elasticsearchの検索インデックスの作成で使用しています。
(Q4)どんな風にElasticsearchとリアルタイム連携してますか?
(A)リアルタイムデータから数分ごとに検索インデックスを作製してElasticsearchの方に反映しています。
(Q5)GCP側でCloud SQLを直接叩かずにBigQueryを経由するのはなぜですか?
(A)BigQuery上にあるデータとJOINできるというのが一番大きな理由です。今回ですとCloud SQLからしかBigQueryに連携しないように見えてしまったかもしれませんが実際は他のいろんな経路からもBigQueryに連携しています。Cloud SQLを直接書くとBigQuery上の他のテーブルとJOINできないので、一旦BigQueryに全部集めてデータのJOINを行なっています。
(Q6)どれだけのデータ量に耐えているのですか?
(A)データ基盤全体だと数百TBはあります。BigQueryはほぼ無限にデータを入れられるので、その点にも魅力を感じています。
(Q7)登壇社全員に聞いてみたい データ分析の一番の失敗談(ビジネス系でもテック系でも)
(A)最初にデータ分析基盤チームにジョインした時、システム全般を見渡さずにアーキテクチャを考えてしまい、仲のいいチームでデータを取りやすそうなところからデータを取ってしまったのが失敗談です。そのせいで本来取得するべき箇所から取得するように修正するのに1年くらい時間がかかってしまい、修正中にデータ欠損が発生するなどの問題もおこしてしまいました。
平野さんへの質問
(Q1)スクラム、エンジニアチーム以外にも導入してるんですか?
(A)組織全体で見ると導入しているチームもあります。
(Q2)データカタログはどういったアーキを使っているんでしょうか?
(A)スプレッドシートを使ったお手製のBIツールを使って、BigQueryのテーブル名、カラム等のメタデータを取得し、スプレッドシートに吐き出し、そこからスプレッドシートが走っているような感じです。
(Q3)登壇社全員に聞いてみたい データ分析の一番の失敗談(ビジネス系でもテック系でも)
(A)データ分析基盤の失敗談は多いです。使われないデータ基盤を作ったこともありました。BigQueryでDWSを採用していますが、そこまでのデータパイプラインをこだわり、必要以上にいろいろなツールを入れてしまい、最終的に利用者にとって使いにくいものとなってしまったことがありました。それから、できるだけ無駄な技術を排除してシンプルな構造にしていくようになりました。
イベントレポートは以上となります!
最後に、今回登壇してくださった皆様、参加してくださったみなさま、ありがとうございました!次回もお楽しみに!♪
