


こんにちは!TECH Street編集部です!
今回は2022月1月27日(木)に開催した、 「データ分析基盤エンジニア勉強会~各社の取り組みや課題から学ぶ会~」のイベントレポートをお届けいたします。
登壇者はこちらの皆さま!
・ 樋口 裕介さん/株式会社LIFULL
・ 鈴木 裕之さん/パーソルキャリア株式会社
・ 楊 明さん/株式会社カカクコム
それでは早速ご紹介していきます。
4年間の運用で見えてきた、LIFULLデータ基盤のいい点・悪い点
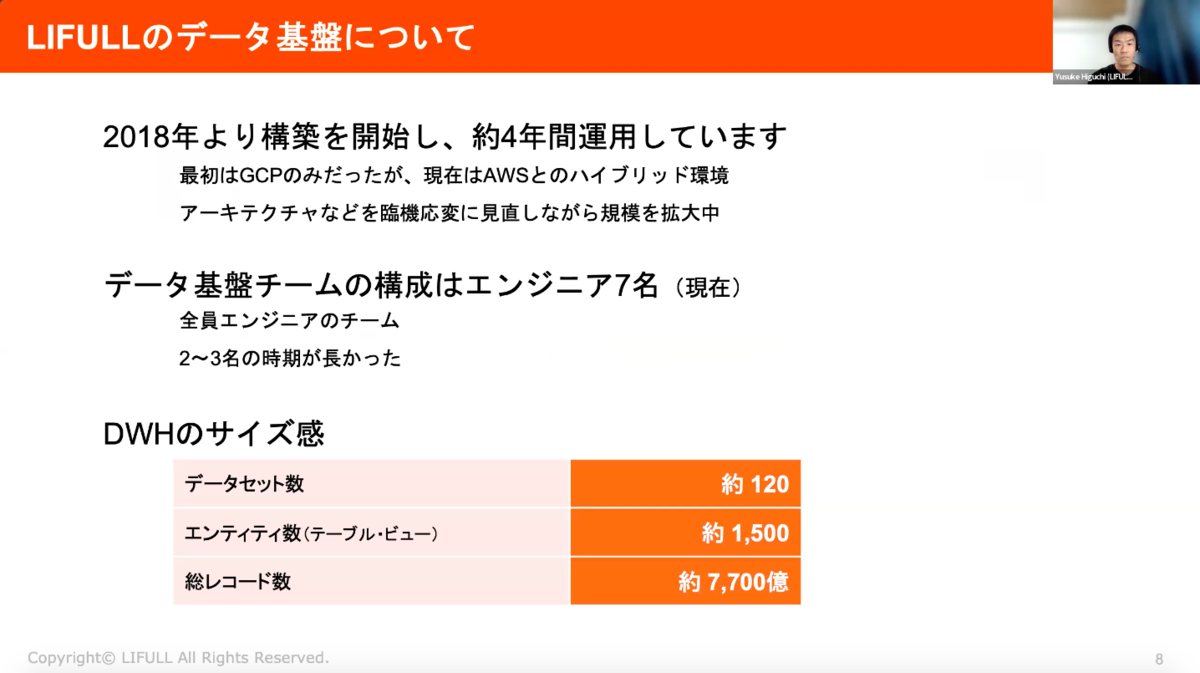
LIFULLのデータ基盤は2018年より構築を開始し、約4年間運用しています。最初はGCPのみでしたが、現在はAWSとのハイブリット環境において、アーキテクチャなどを臨機応変に見直しながら規模を拡大中。
データ基盤チームの構成はエンジニア7名。データウェアハウスのサイズは、下記の通りです。
・データセット:約120
・エンティティ数(テーブル・ビュー):約1,500
・総レコード数:約7,700億
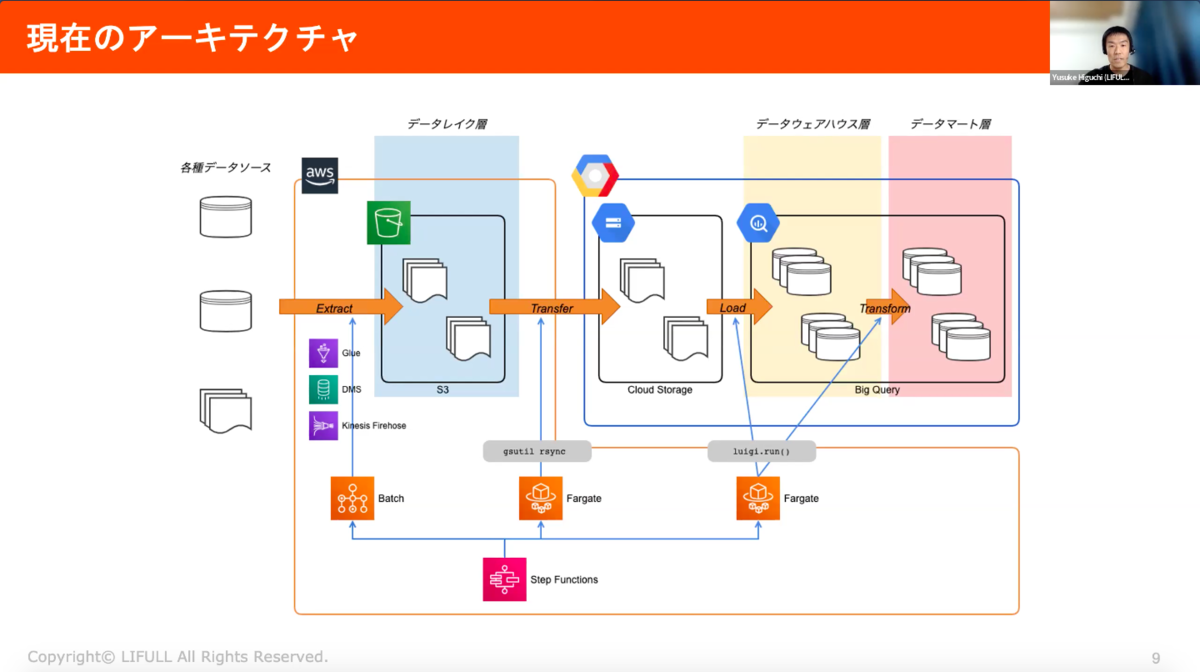
現在のアーキテクチャはこちら。データレイク、データウェアハウス(DWH)、データマートの3層に分かれた構成になっています。データパイプラインの全体は、AWS Step Functionsでコントロールしており、BigQueryの部分はLuigiを使っています。
ここからは、「いい点と改善したい点」についてお話します。
いい点
①DWHにBigQueryを採用したこと

BigQueryはGoogle Workspaceとの相性が良く、権限を付与するだけで誰でも使うことができ、かつ、非エンジニアでも使いやすいUIであることから非常に便利です。また、新機能のリリースが頻繁に行われるため、現時点で「機能が弱い」と思う点があっても待っていれば解消される可能性もあり、その点も便利なポイントです。
②ETLではなくELT

Extract → Load → Transformというフォームになっていることもポイント。まずはBigQueryにロードしてから変換・加工の処理を行うことで、加工の処理のためのサーバーやクラスターの管理から解放されています。
また、変換・加工の処理はSQLで記述することができます。データ基盤などの経験がなくてもSQLをかける人は多く、実際に大体の加工処理はSQLで実現することが可能となっています。また、SQLをWebコンソールでもすぐに動作確認することができるため、デバッグも容易。依頼者からの要望をSQLでやりとりして、そのままバッチに実装することもできます。
このLoad→Transformの部分ですが、具体的には外部テーブルから処理を開始しています。Cloud Strage上のファイルを一時的な外部テーブルで参照するところから処理を開始することで、Load用の中間テーブルを準備することが不要になりました。
③TransformのパイプラインはLuigi
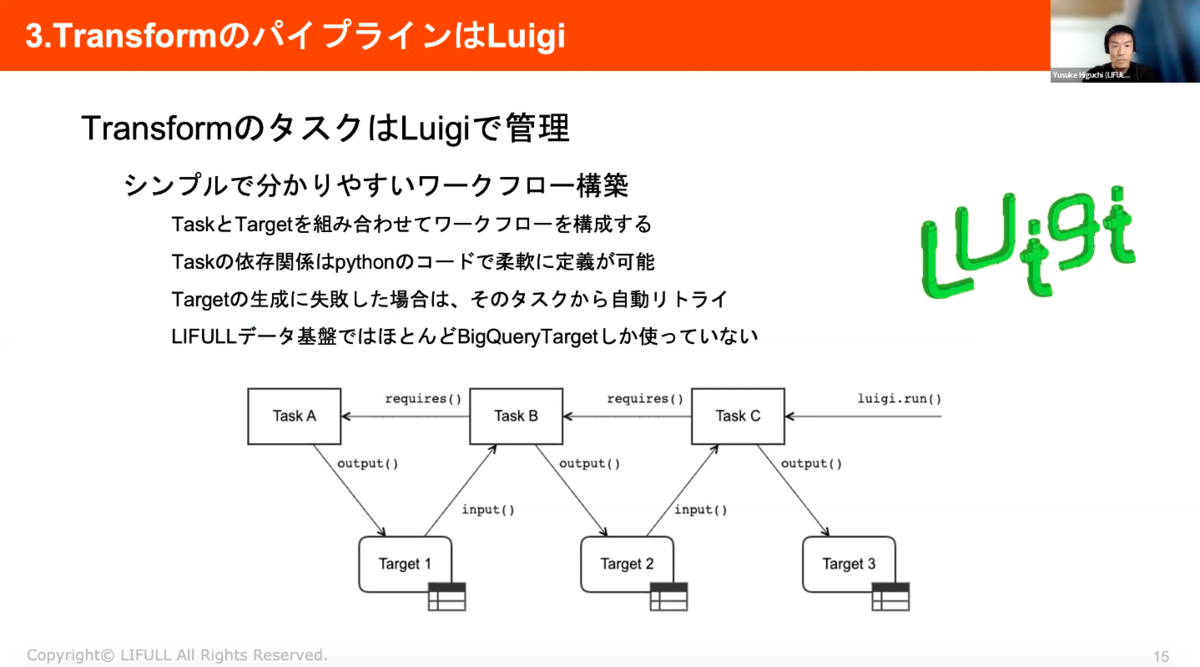
TransformのタスクはLuigiで管理することで、シンプルでわかりやすいワークフローを構築することができています。TaskとTargetを組み合わせてワークフローを構成することで、Taskの依存関係はPythonのコードで柔軟に定義が可能になります。この図だとABCの順番でTaskが実行されていきます。Targetの生成に失敗した場合は、そのタスクから自動でリトライされていきます。
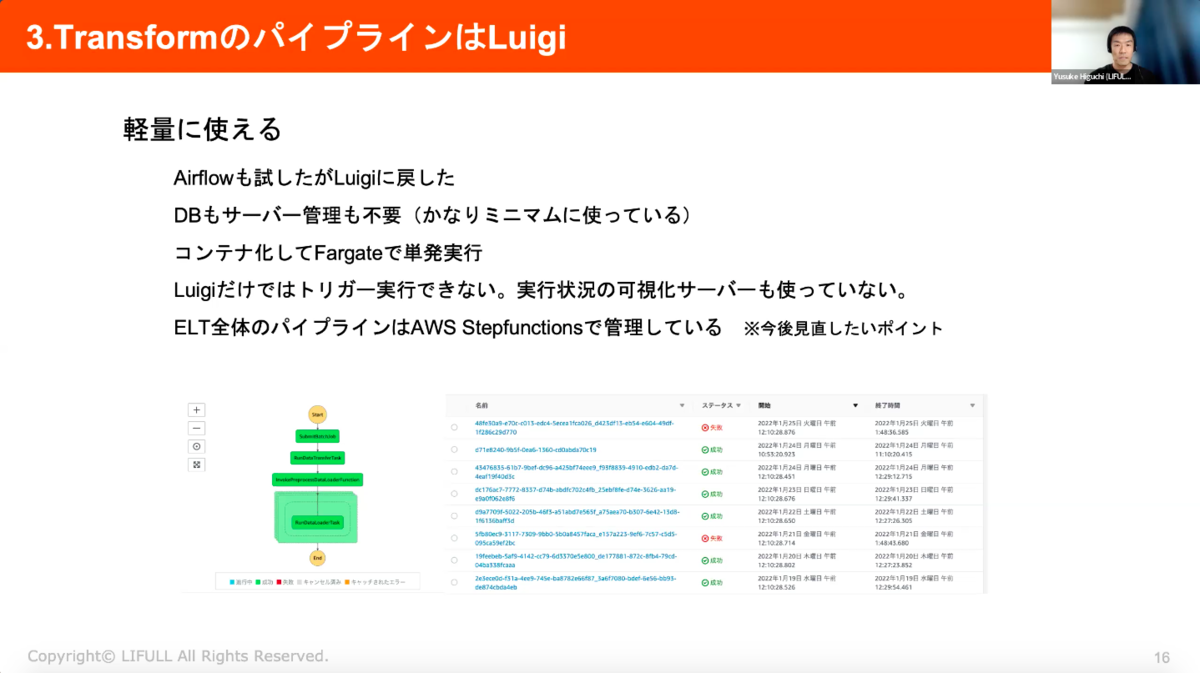
また、非常に軽量なのもポイント。一時期、Airflowも試しましたが、Luigiに戻しました。DBもサーバー管理も不要でミニマムに運用することができ、コンテナ化してFargateで単発実行することも可能です。Luigiだけではトリガー実行ができず、実行状況の可視化サーバーも使っていないため、ELT全体のパイプラインはAWS Stepfunctionsで管理している、という点は今後見直したいポイントです。
続いて、改善したい点について紹介します。
改善したい点
①Extractの処理が煩雑
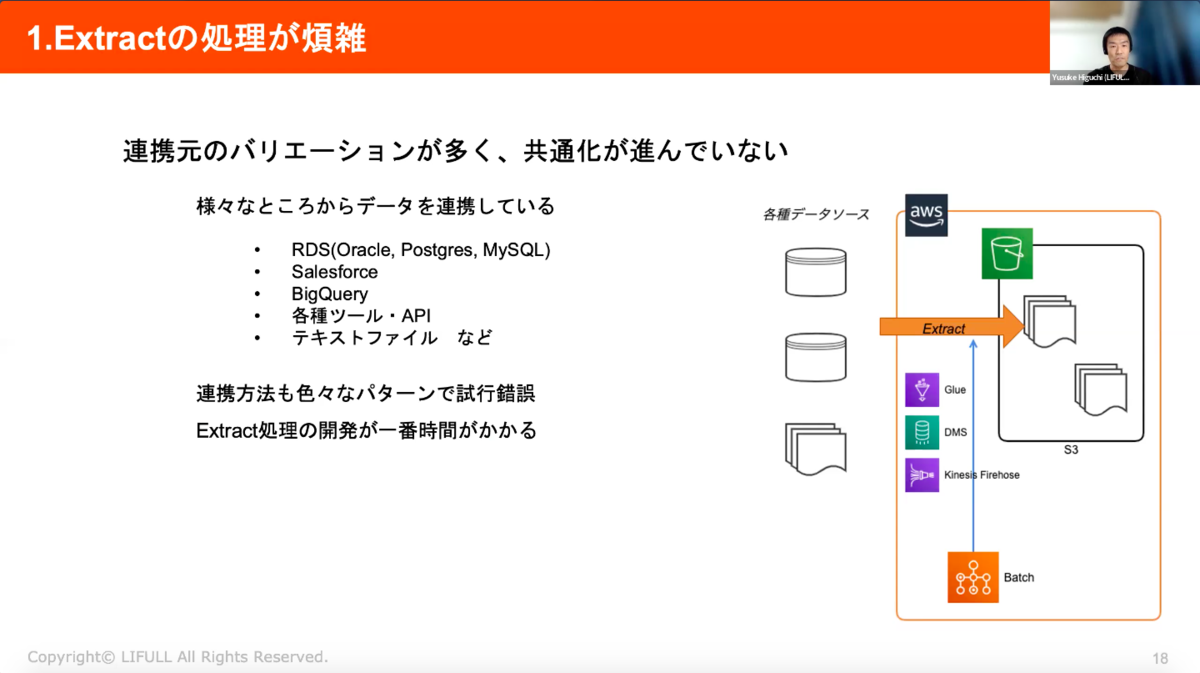
連携元のバリエーションが多く、共通化が進んでいないため、様々なところからデータ連携する必要があります。連携方法のパターンも様々で、試行錯誤が必要...Extractの処理の開発に一番時間がかかっているため、ここは改善したいです。
具体的には、下記のような様々な連携パターンを実装してきました。
・AWS Glueで接続して抽出
・Data Migration ServiceでCSVに変換
・RDSスナップショットをデータ基盤側で復元するパターンも
・OracleにSQL*Plusでクエリ実行
・REST APIからデータ取得
・連携元ツールからFirehose経由で連携
・他のBigQueryテーブルからビューで連携
・テキストファイルを利用者にアップロードしてもらう
②GCPとAWSの併用(マルチクラウド)
データ基盤はBigQuery中心となりますが、会社全体ではAWSの利用が多いため、連携元はAWS環境であることがほとんど。社内にAWSのナレッジが溜まっているため、AWSに詳しい人の方が多く、AWS Organizationsによる一元管理のメリットもある状況です。
また、データレイクはAWS S3、DWHはBigQueryという環境のためS3→GCS間でファイル転送をする必要があります。
この点については、BigQuery Omniによる解消を期待しています。BigQuery Omniとは、BigQueryからAWS S3やAzure Blob Storageのデータに対してクエリが実行できるため、S3→GCSの転送処理を省けるのではないかと期待しています。
③利用者に編集権限がない

利用者には参照権限のみを提供していることから、簡易なデータマートの作成やテーブルのDescription設定など、全ての作業がデータ基盤チームに依頼される状態となってしまい、対応に時間がかかってしまっているのが課題。
今後は、データマート領域は利用者に管理権限を解放していく方向で準備を進めていますが、データ規模や利用者の拡大に伴った運用面の効率化が重要な注力ポイントです。
分析システムで頻発する夜間バッチのシステムエラーから安眠を取り戻す!
データ分析、AI、BIを企画運営し、パーソルグループ全社で活用できるよう推進することに従事している鈴木さんからは、データ分析環境の導入から改善までについてご共有いただきました。
まず、データ活用を推進するにあたって、下記のようなビジョンを掲げて導入を開始しました。
・ビジネスとして実務的に利用するべく環境が整っていること
・データサイエンスの活用サイクル(モニタリング、課題定義、データ探索予測モデル、施策展開)が運営できていること
・管理体制を置き、セキュリティ管理が徹底され安全に利用できる環境になっていること
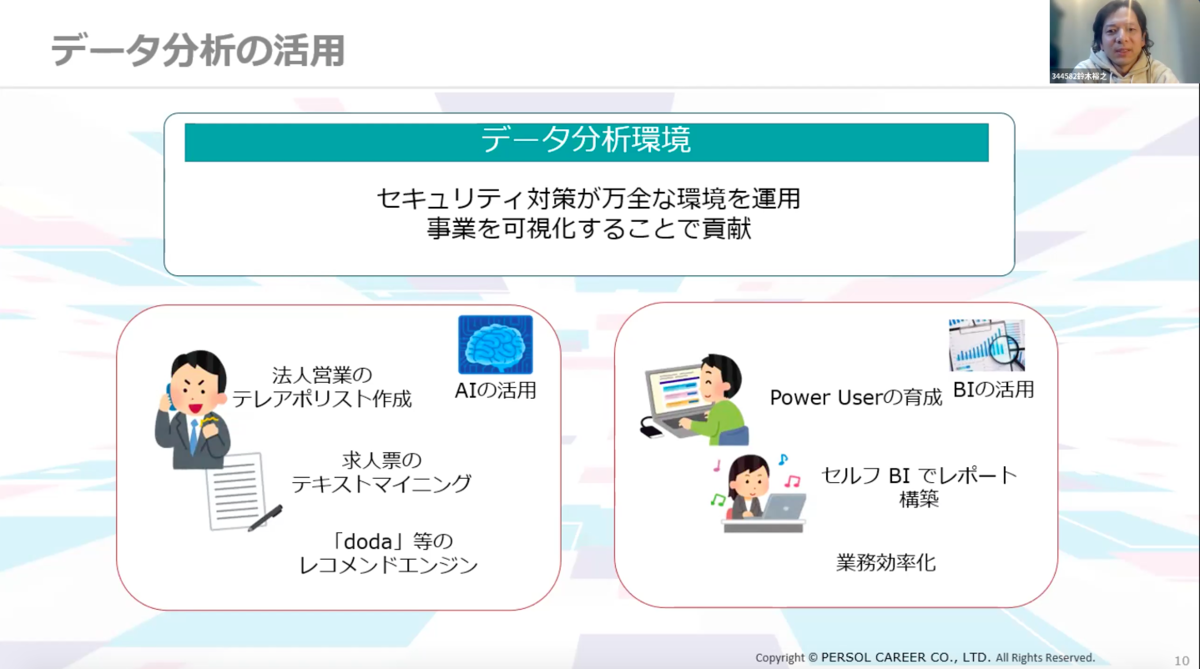
データ分析環境のセキュリティ対策を万全にし、事業を可視化することでデータ分析を活用・貢献することを目指しました。例えばAIの活用においては、法人営業のテレアポリストの作成、求人票のテキストマイニング、「doda」等のレコメンドエンジンを想定。また、BIはPower Userを育成し、セルフBIでレポート構築し、業務効率化ができることを目指しています。
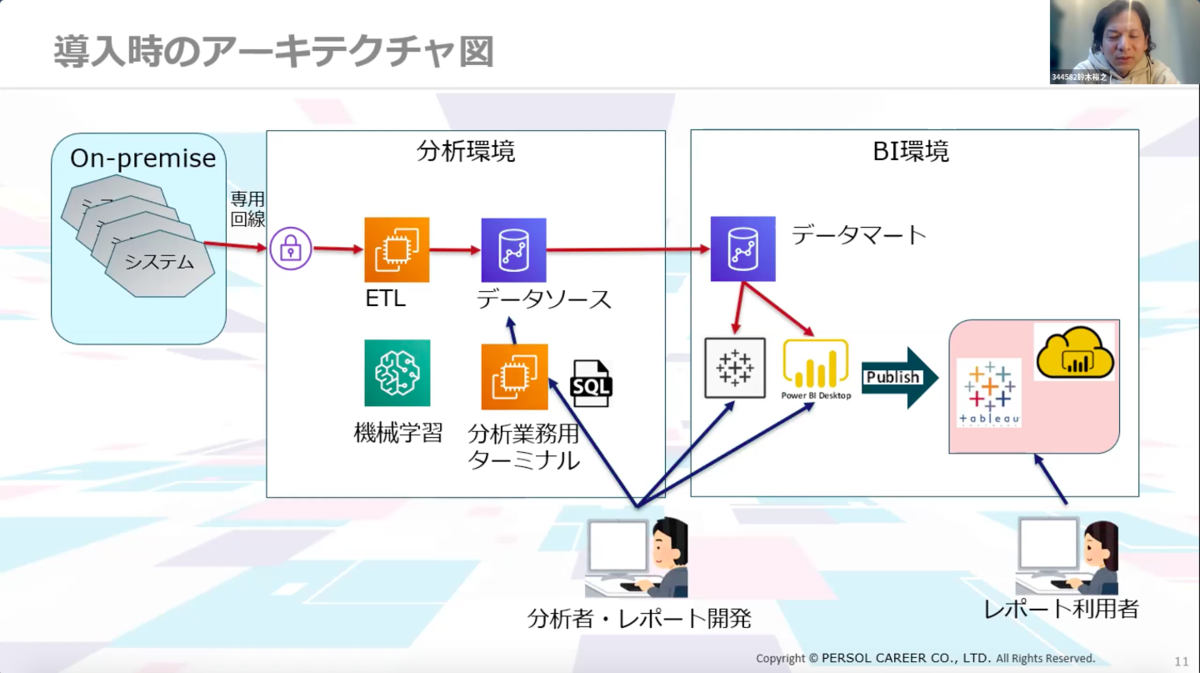
こちらが導入時期のアーキテクチャ図です。オンプレにあるシステムをデータ連携し、ETLを通してデータソースとしてデータを蓄積します。分析環境の中にはRedshiftがあり、Redshiftの中には求人情報などのセンシティブなデータが存在しています。このデータを扱う分析者のデータは分析業務ターミナルで把握できるようになっています。
集計をかけたデータは可視化するためにBIツールを活用。BIツールは利用者も多いので別環境で用意しています。開発者がPower BIやTableauでレポート作成した後、パブリッシュし、Webでレポートが参照できるようになっています。
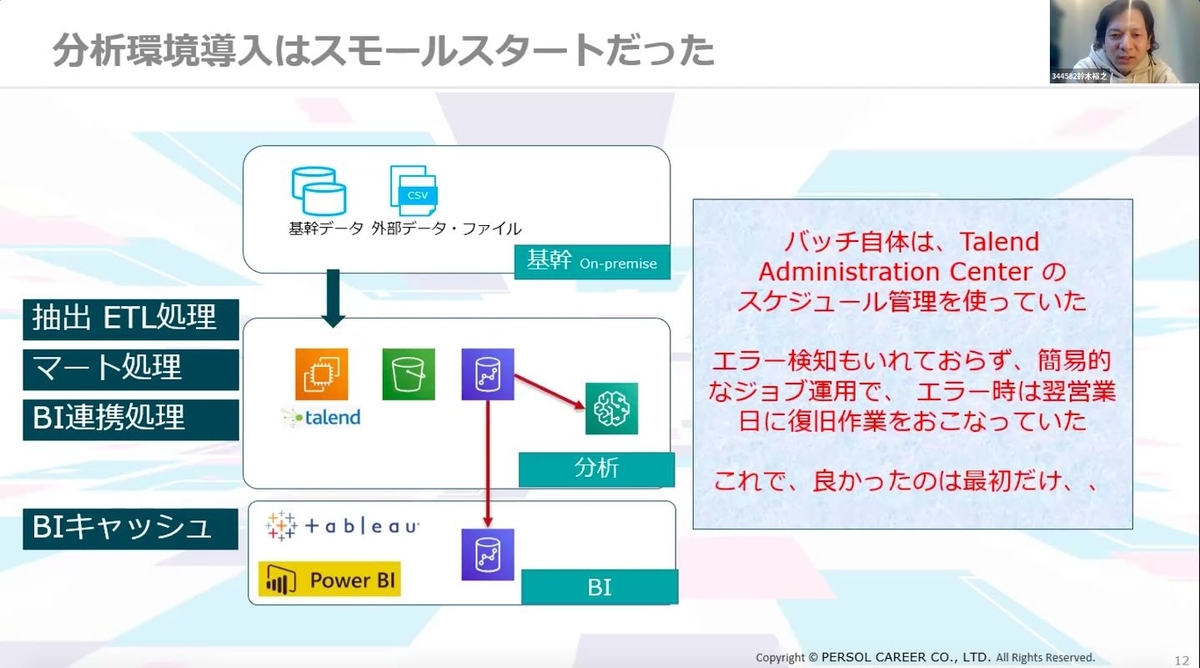
分析環境の導入は2018年から開始しましたが、初めはスモールスタートでした。当時、バッチ自体はTalend Administration Centerのスケジュール管理を使っており、バッチ管理というよりは、ジョブをウォッチしているような形で、分析に特化していたため、エラー探知も入れず、エラーが起きると翌営業日に復旧作業を行なっていました。
最初はこの形でも問題ありませんでしたが、あっという間にテーブル数が1万超に…!
BI利用者数は2,000名にまで増加し、始業時刻にデータ集計が間に合わないなど、環境負荷が進むにつれて課題が山積みになってしまいました…
そこで、まずは夜間バッチの改善に着手することにしました。

マートが利用するデータソースをSQLからピックアップし、処理のコントロールを行うことで、ジョブ課題を解決することを目指しました。これにより、スレッド起動による負荷が分散されて、BI環境までの時刻は大きく改善。
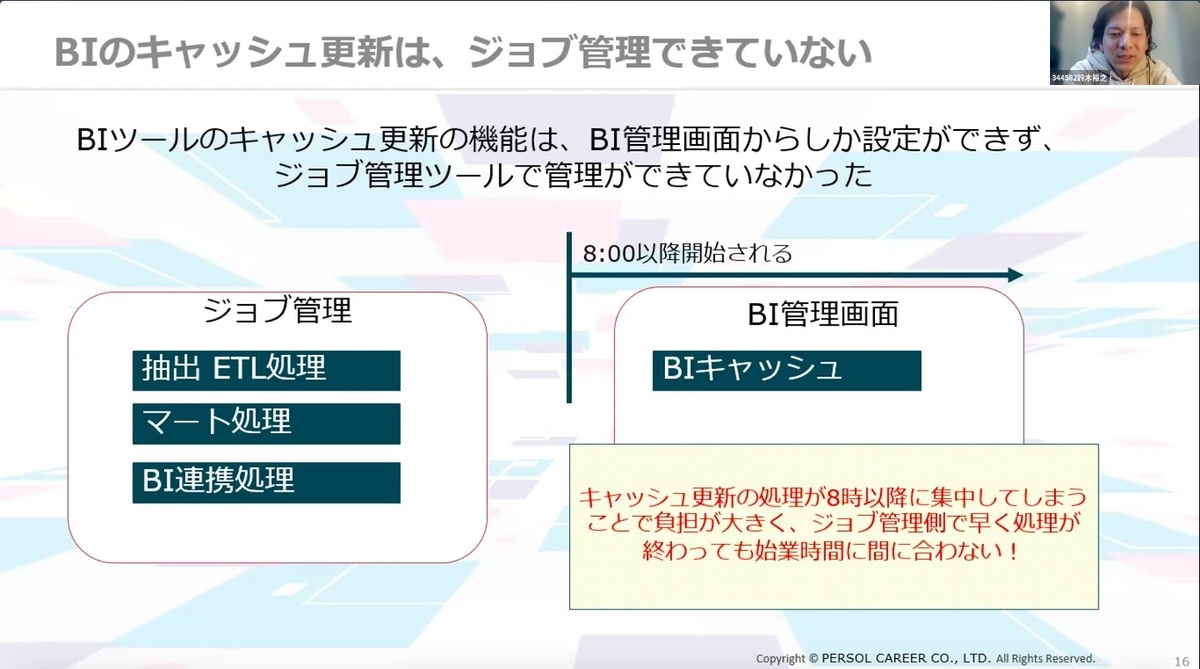
抽出ETL処理、マート処理、BI連携処理は早く終わるようになったものの、BIツールのキャッシュ更新機能は、BI管理画面からしか設定ができず、ジョブ管理ツールで管理ができない状況であったためさらなる問題が発生しました。キャッシュ更新の処理が8時以降に集中してしまうことでBIキャッシュの負担が大きくなり、ジョブ管理側で早く処理が終わっても始業時間までに処理が間に合わない状況になりました。
このキャッシュ更新をどうするかが次の課題です。
PowerBIのキャッシュ更新は、管理コンソールの中で、レポート単位でキャッシュ更新時間を設定していました。そのため、8時から12時ごろまでにレポート更新が集中し、高負荷の時間が継続してしまっており、ここを別の方法に切り替える必要がありました。
そこでBI ServiceのAPIを利用することに。【ジョブ管理から直接BIレポートを更新すること】ができればここの問題が解決できると考えました。
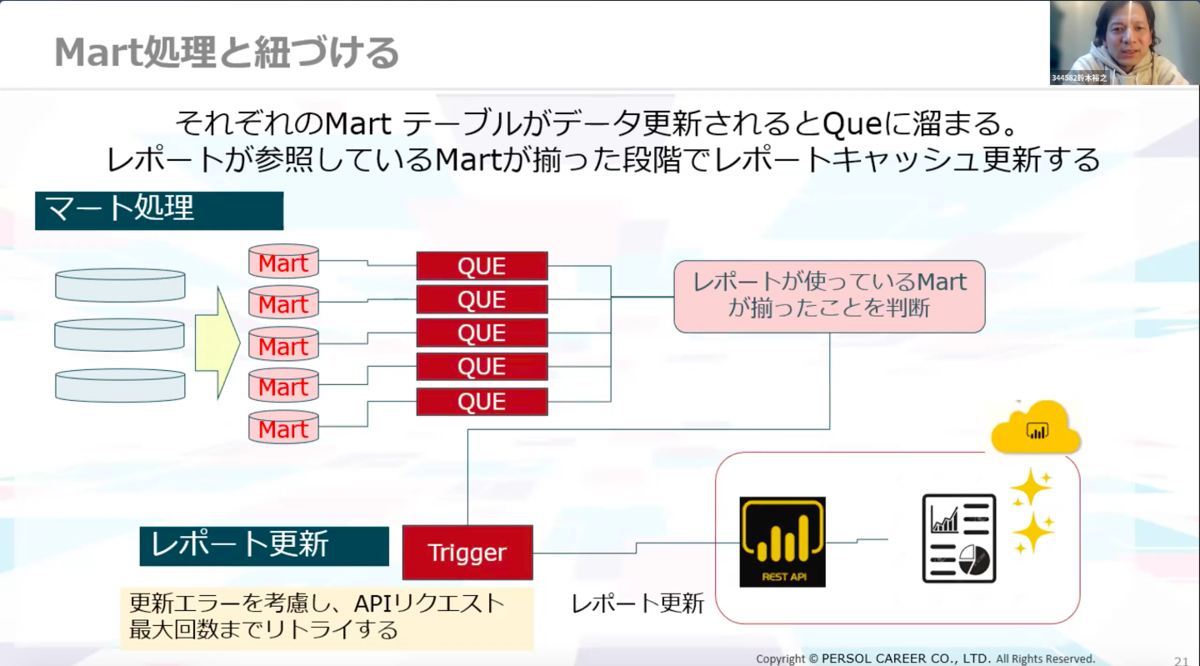
それぞれのMartテーブルがデータ更新されるとQueにたまり、レポートが参照しているMartが揃った段階でレポートキャッシュ更新するように、API化を試みました。
ジョブ管理でBIキャッシュまで扱えるようになったことで、随時自動更新に移設することができ、安定運用の目処が立ちました。
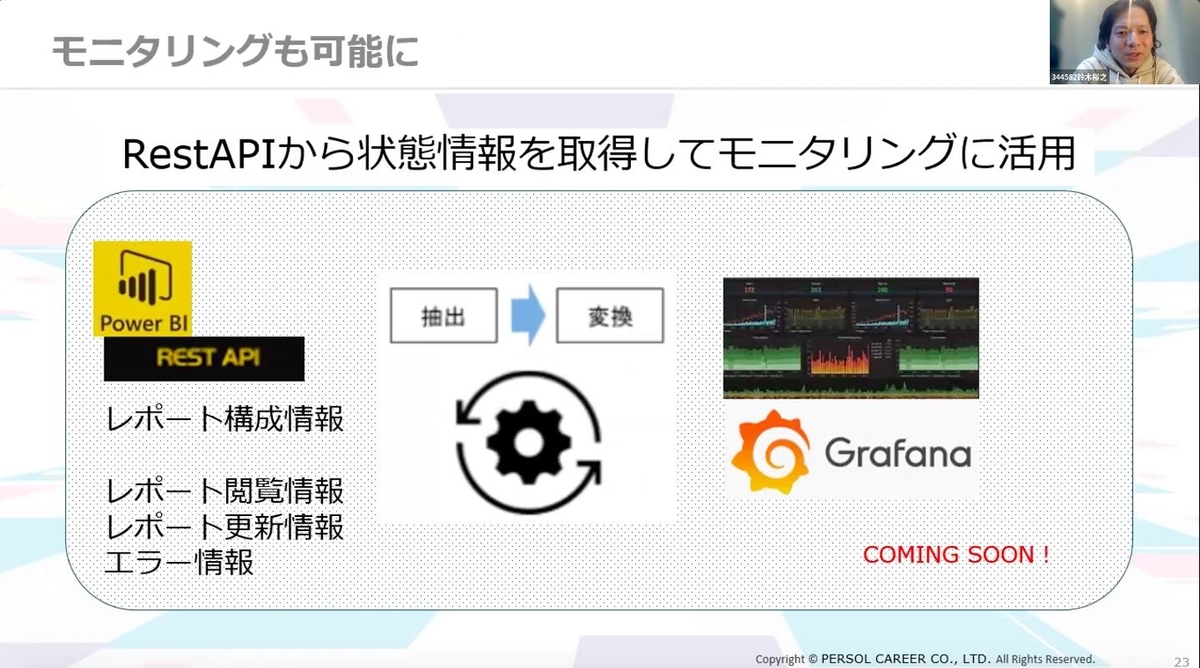
これによって、RestAPIから状態情報を取得してモニタリングに活用することもできるようにすることも検討しています。
運用改善
レポート開発のDesktopはWindowsServerで実施するようにしていましたが、レポート開発者は数百名にまで増加したためサーバーは5台体制に。ユーザーの割り振りやアカウント管理、ツールのバージョンアップ対応などのサーバー管理が負担になっていき、下記のようなポイントを改善したいと考えるようになりました。
・ユーザーにどのサーバーを使うのかを判断させたくない
・アカウント管理を一元化したい
・どのサーバー利用でも資材を参照したい
・アップデートを簡易化したい
まずは分散の処理について。RD接続ブローカーを導入したことで、セッションの負荷分散を自動化。これにより利用者はどのWindowsServerに接続するかは意識せずに分散してRDPすることができるようになります。
アカウント管理
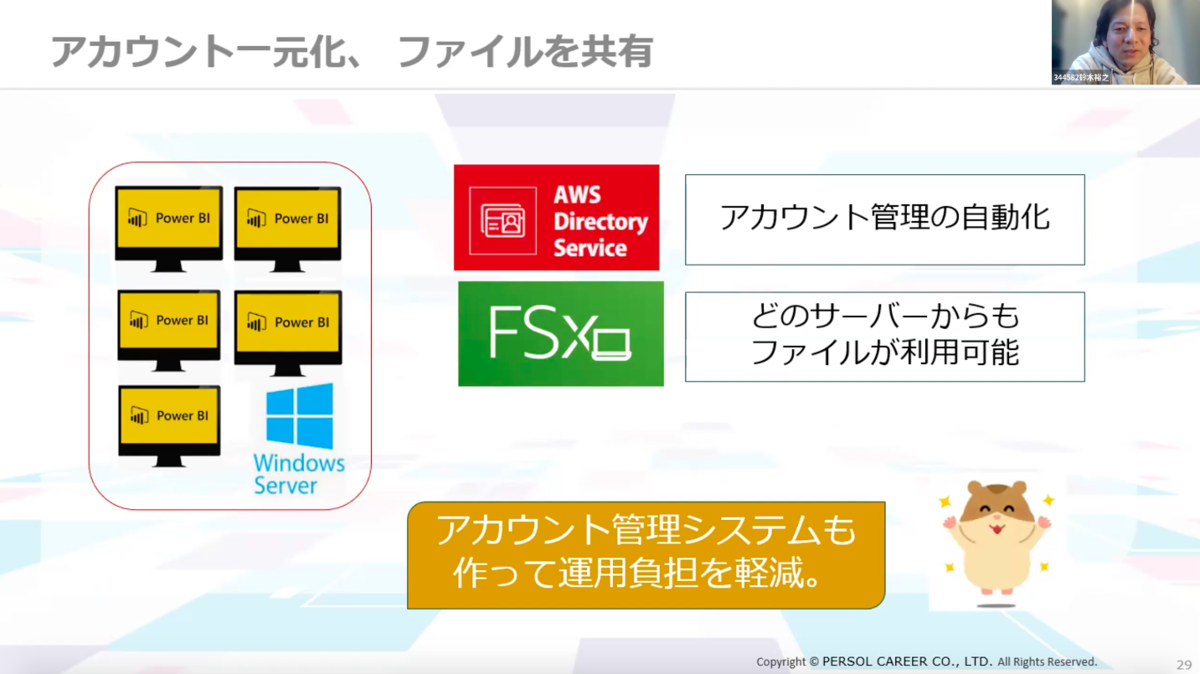
次にアカウント管理について。AWSのDirectory Serviceを導入し、アカウントを一元化、どのサーバーからもファイルを利用できるようにしました。また、アカウント管理システムを作って運用負担を軽減することにも成功しました。
アップデートの簡易化
続いて、アップデートの簡易化について。こちらは1台ずつのWindowsUpdateやPowerBIDesktopのVersion Upを一括まとめて実行することで、寝ている間にメンテナンスが終了できるように◎
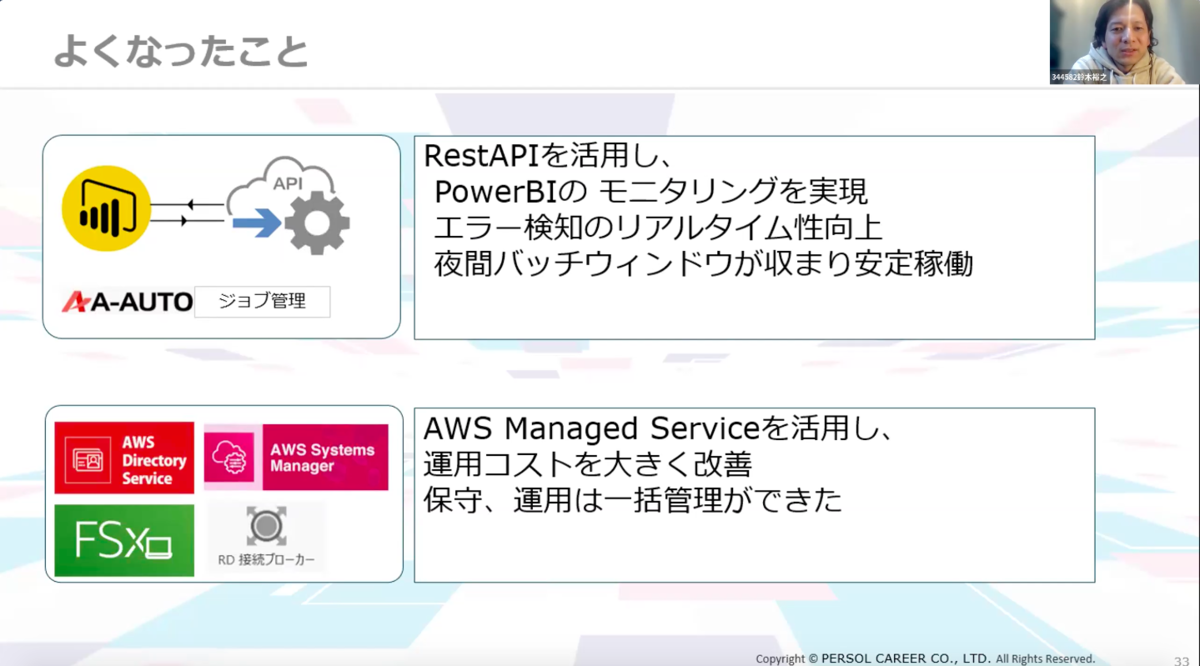
RestAPIを活用し、PowerBIのモニタリングを実現することで、エラー検知のリアルタイム性が向上し、夜間バッチウィンドウが収まり安定稼働につなげることができました。また、AWS Managed Serviceを活用することで運用コストは大きく改善。保守・運用は一括管理ができるようになりました。
今後は、以下のような施策を考えています。
・ユーザー分析の強化
事業の変革とともに、分析スタイルも変化してきており、現環境ではスペックや構成を見直しする必要が出てきている
・プライバシーデータ管理強化
データセキュリティの効率化、法改正に伴う取り扱いの変化に対応していくコンプライアンス管理を検討中
・Tableauのデータ更新も自動化していくこと
夜間のバッチエラーはまだまだ課題があるためシステム障害時の自動復旧を今後も検討
食べログのビッグデータ基盤を支える技術
続いて、食べログのビッグデータ基盤を支える技術について楊さんからお話いただきます!
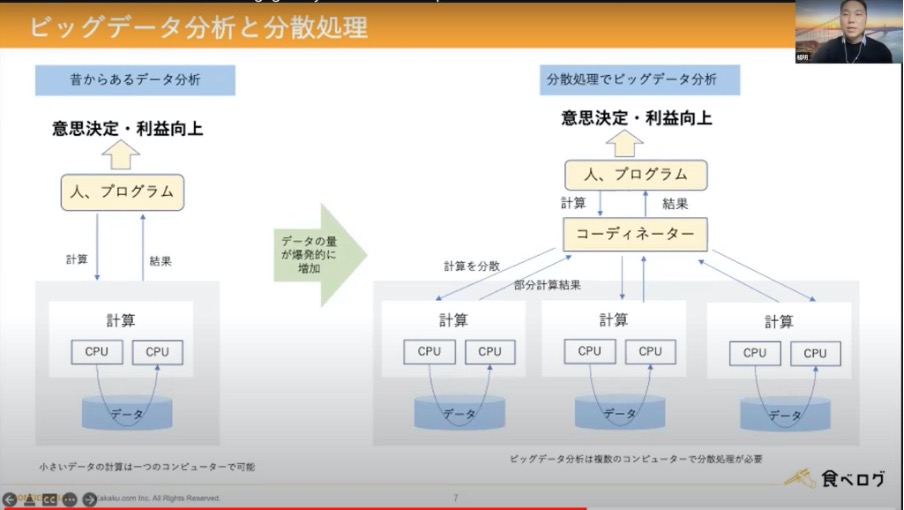
データを分析するという取り組みは昔から存在していたもののデータ量が爆発的に増加したことで、分析が単一のコンピュータで完結することができなくなり、分散処理をして行う必要が出てきました。
また、インターネットやスマートフォンの普及により、画像や音声データが増加し、これらの非構造データを分析するために、機械学習による処理も必要となりました。
分析基盤の全体像
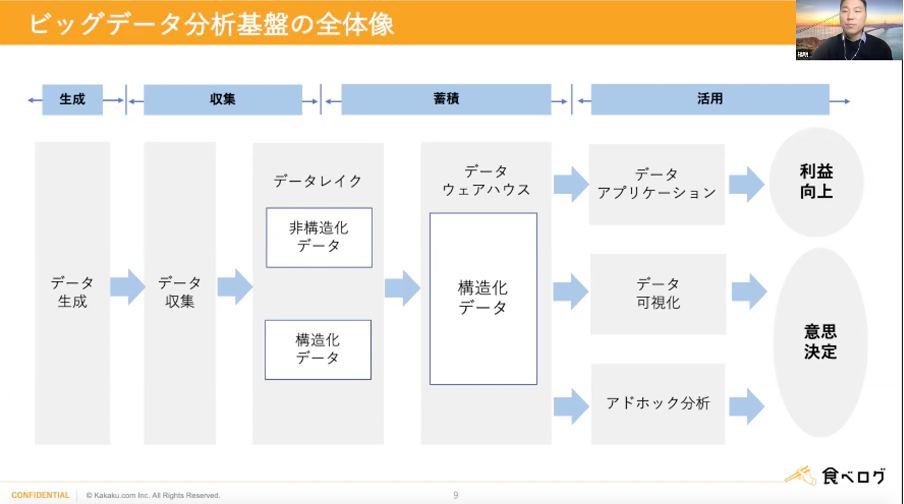
これらの処理を叶えるためにビッグデータ分析基盤が必要となります。生データを収集し、データレイクでは非構造化データと構造化データが混ざっており、データウェアハウスで構造化、その後データアプリケーションやデータ可視化、アドホック分析をして利益向上や意思決定につなげていく流れとなります。
ビッグデータ要件
続いて、食べログのビッグデータ要件についてです。食べログのビッグデータ基盤は下記のようなことを目指して開発が進められました。
①食べログのあらゆるデータがビッグデータ基盤に集約されている
・データサイズが大きく、かつ、本数が多い。
・ログデータとスナップショットデータがあり、ともに非常に巨大なデータを持っている。
・スナップショットデータは過去に遡って集計したいことが度々ある。
②社内のあらゆる人がデータドリブンな意思決定をできるようにする
・クエリの実行は様々な部署が行うため、時間帯がよく重なる。そのような状況でも待機することなく集計作業を実施したい。
・ITリテラシーが低い人でもデータ分析できるようにする。
③データを活用した機械学習やAIプロダクトでビジネスに貢献する
・簡単にMLモデルを構築&デプロイできる環境を作れるようにする。
・手軽に機械学習をアプリケーションに組み込むことが可能。
食べログのビッグデータ基盤の全体図は上記のようになっています。全ての構成はGCP上に存在します。
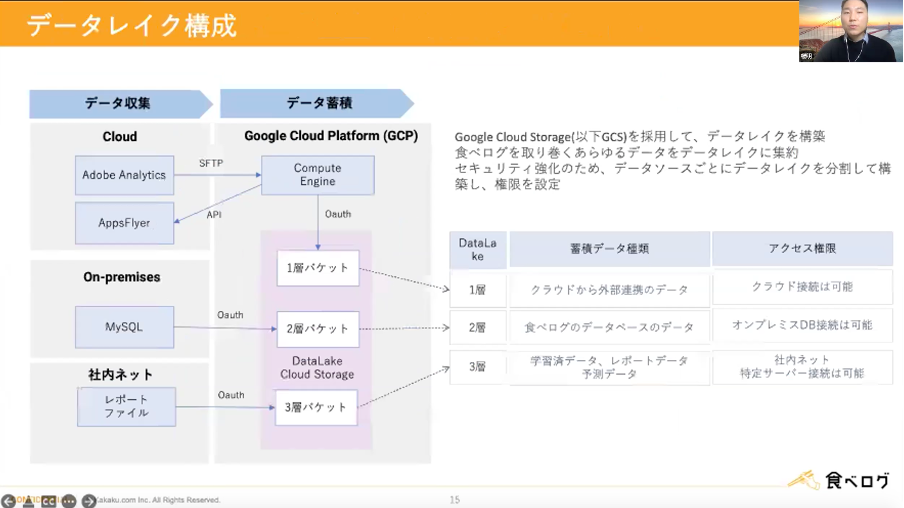
食べログのデータレイクはGoogle Cloud Storageを採用し、構築されています。食べログを取り巻くあらゆるデータをこのデータレイクに集約し、セキュリティ強化のため、データソースごとにデータレイクを分割して構築し、権限を設定しています。
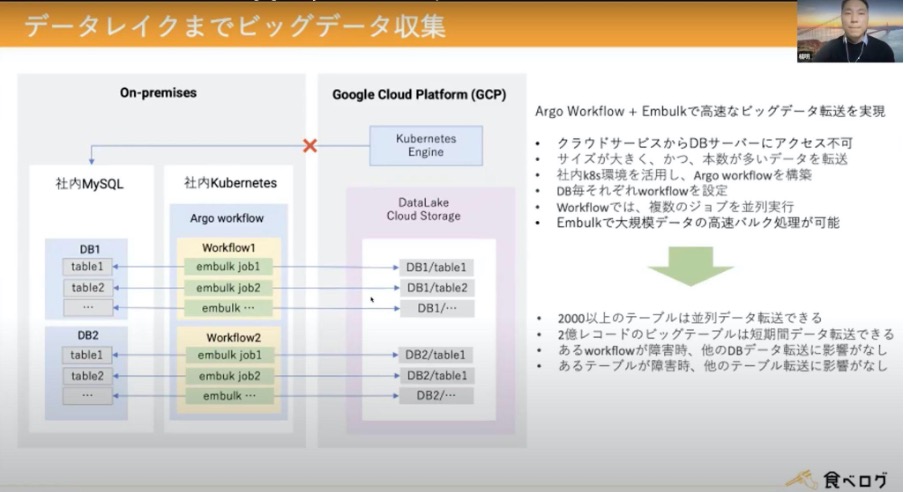
データレイクまでのビッグデータ収集は、Argo Workflow + Embulkで高速なビッグデータ転送を実現しました。
・クラウドサービスからDBサーバーにアクセス不可
・サイズが大きく、本数が多いデータを転送
・社内k8s環境を活用し、Argo Workflowを構築
・DBごとそれぞれのWorkflowを設定
・Workflowでは、複数のジョブを並列実行
・Embulkで大規模データの高速バルク処理が可能
このような条件により収集し、2,000以上のテーブルは並列データ転送ができ、2億レコードのビッグテーブルも短期間データ転送ができるようになりました。また、Workflowの障害が発生しても他のDBデータ転送には影響がなく、テーブルの障害発生時も、他のテーブル転送には影響がない形となりました。
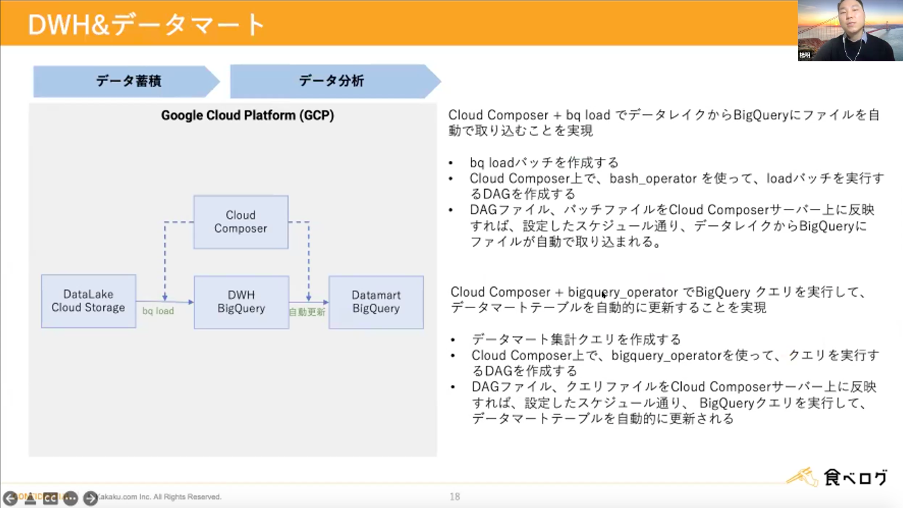
続いて、データウェアハウスとデータマートについてです。こちらは下記の流れでCloud Composerとbq loadでデータレイクからBigQueryにファイルを自動で取り込むことを実現しました。
・bq loadバッチを作成
・Cloud Composer上で、bash_operatorを使って、loadバッチを実行するDAGを作成
・DAGファイル、バッチファイルをCloud Composerサーバー上に反映すれば設定したスケジュール通りデータレイクからBigQueryにファイルが自動で取り込まれる
また下記の流れでCloud Composerとbigquery_operatorを使ってクエリを実行、データマートテーブルを自動的に更新することも実現しました。
・データマート集計クエリを作成
・Cloud Composer上でbigquery_operatorを使ってクエリを実行するDAGを作成
・DAGファイル、クエリファイルをCloud Composerサーバー上に反映すれば設定したスケジュール通りBigQueryクエリを実行してデータマートテーブルを自動的に更新
データマートを作成しなくても、データウェアハウスにあるデータだけで活用することも可能ですが、汎用的なデータマートを作成することで計算リソースの削減を目指しました。
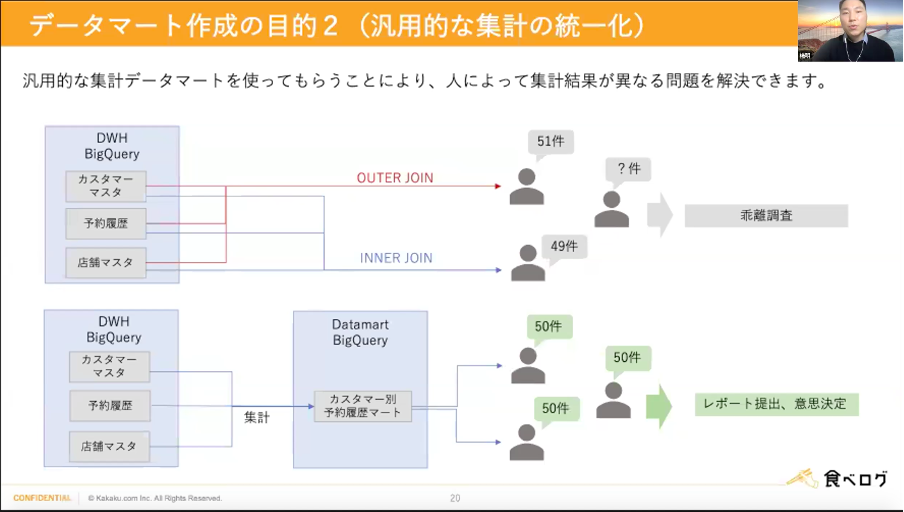
また、汎用的な集計データマートを使うことにより、人によって集計結果が異なる問題を解決することを目指しました。
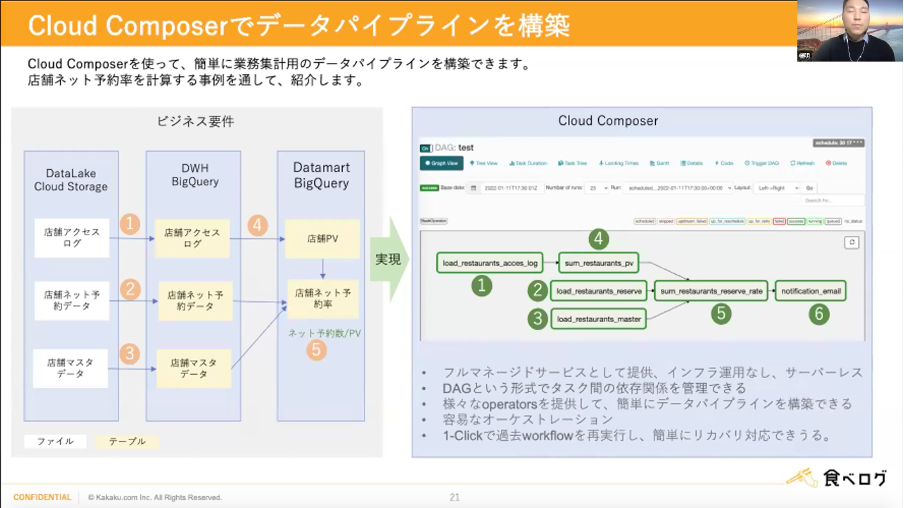
続いて、データパイプラインについてですが、こちらはCloud Composerを使って簡単に業務集計用のデータパイプラインを構築することができます。店舗ネット予約率を計算する事例が上記図の流れとなります。
このCloud Composerは下記のような利点があります。
・フルマネージドサービスであるため、インフラ運用なし、サーバーレスにできる
・DAGという形式でタスク間の依存関係を管理することができる
・様々なoperatorsを提供して簡単にデータパイプラインを構築できる
・容易なオーケストレーション
・1-Clickで過去Workflowを再実行し、簡単にリカバリ対応ができる
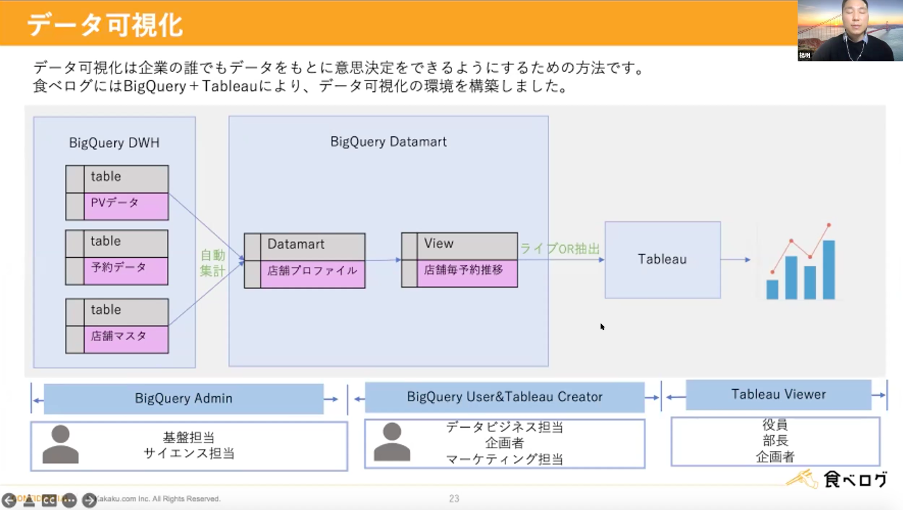
これらのデータはBigQueryとTableauを使ってデータ可視化の環境を構築しました。データの可視化により、企業の誰でもデータをもとに意思決定ができる環境を整えることができました。
まとめ
・セキュリティ強化のため、源泉データの種類別にデータレイクを分割して構築し、それぞれ権限を設定するのがオススメです。
・ビッグデータの収集は容易ではなく、大量のデータを収集するために分散処理が必要です。エンジニアリングにおいても最も工数を費やすのはデータ収集です。
・汎用的な集計データマートを使ってもらうことにより、計算リソースの削減ができ、人によって集計結果が異なる問題を解決できました。
・Cloud Composerを活用することで、データ分析基盤の運用コストをかなり削減できました。
まとめ
参加者からは「初心者なのですが、非構造データの説明とか分かりやすかったです。ありがとうございます。」というコメントが来ていました!本当にここまで教えてもらっていいの?!と思うほどの情報量でお話いただきありがとうございます!
今回もたくさんの質問をいただき大盛り上がりのイベントとなりました!ここからは当日のQ&Aを紹介します^^
参加者から樋口さんへの質問
(Q)ハイブリットにした理由はなんでしょうか?また選ぶ際の選定理由は何になりますでしょうか?
(A)今これがベストかは分からないですが、AWSを会社として主に使っています。なので、AWSを使っている状態。最初は自由にできたので、チャレンジとしてGCPを使っていました。
(Q)2〜3名からさらに人数を増やすことになったきっかけが知りたいです!
(A)世の中的にもデータ活用が注目されているので、弊社も同じ。細かいタスクも2〜3人でこなしていて、手が回らなくなったので規模を拡大しています。
(Q)頻繁なリリースに取り組むのは大変じゃないですか?情報収集も含め、どう対応されていますか?
(A)BQのリリース情報は見るようにしている。社内で情報交換したり、Googleの方から教えてもらうこともあります。
(Q)AWS→GCPだと転送コストがバカにならないと思うのですが、Snowflakeは検討されたりしましたでしょうか?
(A)Snowflake、検討しました。1か月トライアルもした。BQのメリットの恩恵が強いので、抜け出せませんでした。
(Q)ありきたりでごめんなさい。ここまでくるのに一番苦労した点を聞いてみようかな。(やっちゃった系の大失敗とか?)
(A)出所の違うデータを掛け合わせようとした時に、両者の結合キーが存在しないという状態は今も苦労しています。1対Nで結合して按分したりしていますが、元データの整備から進めたいですね。
(Q)利用者が価値を見出している情報はなんでしょうか?
(A)当社では「LIFULL HOME'S」という不動産・住宅情報サイトを運営していることから、物件の情報やユーザーの行動ログなど。情報がいつでも簡単に見られるところに情報の価値を見出しています。
(Q)利用者に参照権限以上の権限を付与する際に気を付けようと考えている事を教えて下さい。
(A)自由にできる権利と共に責任を与えたいです。明確な責任者は仕組みとしておきたい。
(Q)異なるフォーマットの複数のInputを吸収してETLなさっていると思いますが、ここがデータ分析の最も難しい点の1つだと実感しています。結局はInputに合わせてパーサなどを自作するなど、ETLが職人芸化してしまいます。御社でこのような課題に対して工夫していることがあったら聞かせてください :)
(A)1つはAWS等のマネージメントサービスを使って、ここを常に探っています。
(Q)ユーザーは、BigQuery UIを使っていますか? なにかBIツールは、入れていますか?
(A)Tableau Serverをメインで使っています。他にも人によっては別のツールを使っていたりします。
(Q)各社のMDM(マスターデータマネジメント)を具体的にどのようにされているか教えて欲しいです。
(A)ここはまだデータ基盤では管理できていないです。各サービスや社内システム毎に管理されていて、それを単純にデータ基盤に連携するにとどまっています。
(Q)データ基盤を使った機械学習はどんな取組をされていますか(時間の都合で省略とのことでしたが、もし少しだけでもお聞き出来ればお願いいたします)
(A)機械学習などのデータ活用はデータ基盤とは別のチームが取り組んでいます。弊社のテックブログでもいくつか紹介しているので、よろしければ参考にしてみてください。
機械学習 カテゴリーの記事一覧 - LIFULL Creators Blog
(Q)TableauからデータマートでなくViewを参照させている理由を教えてください
(A)「変更が容易」なのがビューを採用するメリットだと考えています。実テーブルの場合だと修正のたびにデータの再作成が必要になるためです。しかしデータマートの内容によっては、ビューのクエリの料金が高い・実行に時間がかかる、などのデメリットが大きく出ることもあるので、その場合は実テーブルにデータを作って提供しています。
(Q)汎用的な集計データマートを作成するにあたり、大変だった点や注力した点を教えてください。
(A)社内の各所のデータをかけ合わせる際に「両者を結合するキーが無い」という状態はかなり厄介です。名寄せしたり擬似的に結合したりしています。データマートに限りませんが、冪等性の担保(=何度でも繰り返し実行できる状態の確保)には気をつけています。
(Q)BigQueryは定額料金ですか?それともオンデマンド料金ですか?
(A)ずっとオンデマンド料金でしたが、最近から定額料金を導入し始めました。併用することが可能なので、少しずつ定額料金に移行しながら検証を進めています。
(Q)汎用データマートを1つ作る場合、どのように進めてどのくらい時間がかかるのか教えてください。
(A)汎用性の度合いによって大きく変わります。一つの部署内で使うものであれば、その部署の方に仕様を決めてもらい(時にはSQLで提出してもらう)、データ基盤チームで実装します。1週間ほどで終わるのがほとんどです。
全社横断レベルのものになると1ヶ月〜6ヶ月くらいかかっています。全社戦略を立てる部署などと一緒に進めますが仕様決め・データ設計に特に時間を使います。
(Q)自由分析するようなユーザーに対しては個別にデータ提供されているのでしょうか?それともデータカタログのようなものを提供する等で対応されていますでしょうか?
(A)データ基盤という単位でアカウントを発行しています。なので、アカウントがあればデータ基盤内のデータをすべて参照できます。利用者はその中で自由に分析が行えます。
参加者から鈴木さんへの質問
(Q)他の領域のエンジニアからデータ分析基盤エンジニアのキャリアチェンジをする場合、どんな取り組みから始めるのが良いと思いますか?
(A)どこに着目したいか、ではないでしょうか。僕は、データサイエンティストにシフトしたかったが、インフラ寄りのことばかりやっています。データモデルを作って色々やっていくのか、インフラ寄りで頑張っていくのかの2つの道があると思います。
(Q)人材系の会社さんという事で「データ分析基盤エンジニア」の需要はどんな感じでしょう?一番必要なスキルってなんなのかな?(目指したい)
(A)弊社は「マッチング」が重要です。その「マッチング」がうまくいく為のデータの持ち方をシステム担当(データ分析)として工夫しています。①候補者にリコメンドできること、②企業側にアプローチできること、この2つの方向に向けた部署があります。重要なスキルとしては「データ知識」であるかと思います。
(Q)BIツールってどう使い分けていますか?
(A)最初は、部署の要望がスタートでした。Tableauはユーザーライセンスなので一定のコストがかかる。一方、Power BIはユーザーライセンスではないので、使い易いです。あとExcelライクなUIでとっかかりやすかった。Tableauはデータドリブンな方々が使っています。
(Q)運用の改善、大変だったと思いますが、その企画・推進も対応も全て鈴木様の部署(何名くらい?)ですか?それとも専用プロジェクトが立ち上がったのでしょうか?
(A)僕の部署でやっています。パートナーをあわせると20名で、社員は8名。それぞれAI担当やBI担当など役割は分かれています。
(Q)一昔前は「ビッグデータでデータサイエンスしたらビジネスが変わる」みたいなファンタジーが世間や経営層に広がっていた気がしていて、最近はそういう考え方がちょっと現実的になった感があります。 パーソルキャリア社ではそのような、ユーザーの意識の変化は感じられますか?
(A)それは大きくあるかもしれません。データ活用したい部署の声は多く届くようになってきました。背景には、データ蓄積からアウトプットの時間が短縮されてきたということがあります。ただ、データ活用で気を付けるべきは「セキュリティ問題」。会社としても個人情報を多くもっているので、もちろんマスキングしているが、個人が特定できないようにするという意識は強く持つ必要があります。最近、この意識が強い人たちが増えてきました。
(Q)こういったエンジニアリングとか開発関連はすべてパーソルテクノロジー(だっけ?)がやっているのかと思っていました。内製なのですね。
(A)そうです!最近は内製が多いです。
(Q)Grafanaのダッシュボード設定は、画面ポチポチでやっていますか? IaC化したいですがあんまりいいアイデアがなくて、結局画面ポチポチでやっています。
(A)試行錯誤中で、ポチポチやっています。良い案があればなぁと思っています。
参加者から楊さんへのご質問
(Q)GCPなのですね。この仕組みにしたポイントはなんでしょうか?選定理由。
(A)そもそもアーキテクチャを選定するときは、2つ以上検討しました。BigQueryのメリットと使いやすさを評価して採用しました。
(Q)k8sの運用ってめちゃくちゃ大変ではありませんか? エキスパートが5人ぐらいいないと、難易度が高すぎてとても運用できないです><
(A)別のチームが管理しています。利用者として僕のチームは使っています。
(Q)大量にデータマートがあると想像しました。 データマートを利用しやすくするための工夫はなにかしてますでしょうか?
(A)データアナリティクスの担当者はとても大変なところですね。作るときはメディア側で使うデータ、ビジネス側で使うデータ等があるので、様々な部門と話し合って、要望に沿ったデータマートの提案・採用を行っています。
登壇者みなさまへの質問
(Q)データの可視化に課題があったら教えてください。
(例)いますぐ改善したい こと、 日常的に不便だと思いつつやや放置状態のこと、長期的にはこうしたいなど。
樋口さん:Tableauを使っていて、最後にBQが飛んできます。仕組みをきちんと理解していないユーザーが使ったときは、とんでもないクエリが飛んでくることもあるのでこれが課題です。
鈴木さん:2つあります。まずは、BIツールの制約。データボリュームの上限があって、やりたい分析が十分にできない。ユーザーがセルフ分析しているので、データマートが沢山存在していて中には似たようなものも...。
楊さん:Tableauを使っています。操作しやすいですが、大量データの読み込みに時間がかかります。共通データマートの個人的に作られたVIEWの管理もしなきゃいけないので膨大な数になって大変です。LaKeel BIも検討しましたけど、しっかり管理が必要で、3人では運用できなかったです。
(Q)データ分析のこの先(未来)、聞いてみたいです。
樋口さん:データエンジニアとしてデータを各社に提供している状態。今は社内共通のデータだが、今後世界にシェアできるようになるといいなと思っています。
鈴木さん:キャパシティの問題。人の動きのデータが増えているので、想像している以上のデータがあります。このボリュームを上手く使いたいので、これを使えるデータ整備を出来ると良いなと思っています。
楊さん:分析シェアのサービスも今後リリースしたい。どんな人でもデータ分析し、意思決定できるものを目指していきたいです。
(Q)個人情報のような秘密情報はどのように保持、権限の管理をされていますか?
樋口さん:エンドユーザーの個人情報はデータ基盤に入れていません。その次に位置するセンシティブな内容はマスキングして入れています。
鈴木さん:DBを分けています。個人情報として入れているスキーマがあり、用途によっては使用を許可し、使い終わったら閉じています。
楊さん:個人情報を使う必要がある人には、権限を与えており、誰かが更新・閲覧をすればそのログを全部残しています。
イベントレポートは以上になります!今後のイベントもお楽しみに◎
