


こんにちは!TECH Street編集部です!
今回は2021年4月27日(火)に開催した、 「Pythonのエンジニア勉強会」のイベントレポートをお届けいたします!こちらは、ITエンジニアが2021年に学びたい(強化したい)プログラミング言語ランキング(※)1位の「Python」について、活用ユーザーが集まり、最新トレンド共有やLTを行う勉強会イベントを開催しました。
登壇者はこちらの3名です!(※登壇順に記載)
久保田 公平さん/パーソルキャリア株式会社
nikkie(にっきー)さん/株式会社ユーザベース
辻 真吾さん/東京大学先端科学技術研究センター
記事前半では、当日の発表内容をレポート、後半では当日回答しきれなかった質問を含めて質疑応答を紹介します◎
PythonとReactを用いて爆速で開発に取り組んだこと
パーソルキャリアでWebアプリケーションエンジニア兼機械学習エンジニアをされている久保田さんからは、Pythonを使って高速でアプリ開発をしたお話を共有していただきました!
開発アプリ概要

今回開発したのは、通勤時間で転職面談をするHR×MaaSのプロジェクトのShowfar というアプリ。
キャリアについて考える余裕がない、積極的に情報収集をするのは億劫だと感じている個人と、優秀な人材になかなか出会えないと感じている企業の両方のニーズを満たすため、通勤時間を活用してカジュアル面談を実施するというものです。

具体的には、まず職務経歴書を作るための仕組み、面談の仕組み、企業から個人への訴求の仕組みを作ることを目指し開発をスタート。今年1月に実証実験を開始し、ユーザーの通勤時間に合わせて配車・面談を予約する機能や、個人情報を取り扱うため情報のマスキングをする機能、オンライン面談用にZoomを連携する機能の実装に取り組みました。
今回の開発はリリース優先で進められ、実際の開発期間は約2ヶ月…!この期間で開発を完了させるために、本当に必要な機能とそうでない機能の精査をし、機能要件の縮小も行いました。
その中で、絶対に外せない考慮すべき点としては下記。
・セキュリティ(個人情報の閲覧可能なタイミングの設定)
・面談確定フローまでの最適化
・メンテナンスコスト(多少かかってもスピードが優先)
セキュリティについては、名前・顔写真・所属などは企業が面談を確定したタイミングで初めて見えるようにするなど、個人情報の優先的に行うことを徹底したサービスとしたそうです。
要件定義・技術選定

技術要件としては、バックエンドはPythonを選択。フロントエンドは、React、TypeScript、Redux Toolkitを使用。また、フレームワークの選定要件を、Djangoをメインとして、サードパッケージとしてDjango REST frameworkをバックエンドのAPIとして叩いて、フロントから呼び出す仕組みにしました。
この開発においては、久保田さんが1人でサーバーサイドを開発していたので、自身が一番知見の深かったPythonを選んだそうです。
実装に至るまでは下記のような案が上がったのだとか。
・Fast APIを使った方が良いのではないか?
・認証はJWTを使った方が楽?
・APIはJWT経由で良いのか?
・GraphQLは使わずにREST APIを使用
・Djangoの管理画面テンプレートを使用したい
・チーム内にDRFの知見が少ないが、学習コストも少ないのでリプレイス前提で作ってしまおう(ロジックは再利用できるようにしておく) など
開発スピードを優先した上で、開発を進められるように技術選定を進めていったのですね…!このように選択をしながら実装をしてみたところ、下記のようなことがわかったそうです。
・Djangoを触ったことがあるのであれば、速度優先/小規模の開発あればDRFは選択肢として有り
・バージョン管理を徹底しないと、バグの原因になる。マイナーバージョンのアップデートであっても動かなくなることがある
・DRFは規模が拡大するにつれて一気に肥大化するので注意
また、運用していく中で気づいたことも。
・DRFは運用しながらの機能改修がきつい
・JWT認証をローカルに保存するのか、クッキーに保存するのかなど、フロントとの連携ができていない箇所があるとうまくいかない。この保存場所はセキュリティに関わるので要注意
・バックエンド側で変更があった際に、本番環境に反映する場合にオペレーションでやるようにしていたが、機能改修が入ってくるので自動化した方が楽だった
この辺りは、最初の段階で決めておかないとスケジュールがおしてしまう可能性があるので注意が必要とのことです!
まとめ
今後の展開について、今回はDjango REST frameworkを使っていたため、相性の良いMySQLを使っていましたが、AWSの運用コストが発生しているため、このコストを下げるためにFirebaseに移行することを検討しているそうです。また、Firebaseの場合はNoSQLを使うことになりますが、その場合はFastAPI等別言語の相性が良いので、それに合わせて変更をかけていくことも検討しているのだとか。
現在は実証実験が終わり、本番サービス化に向けて進行中とのこと!サービスリリースが楽しみですね◎
object活用ことはじめ 〜dataclassと特殊メソッド〜
株式会社ユーザベースでデータサイエンティストをされており、Python歴は3年半のnikkieさん。nikkieさんは2021年のPythonカンファレンス「PyCon JP 2021」の座長も務められている方なのです!
そんなnikkieさんは「dataclass」と「特殊メソッド」を使い始めてPythonが楽しくなったそう。今回は、Pythonを活用するために「Pythonの裏側を知る」をテーマとしてお話いただきました。
Objectとは
PythonにおけるObjectとは「データを抽象的に表したもの」。(ここではオブジェクト指向とは別で、Pythonのオブジェクト=データという話をしていきます。)
また、Pythonの用語集では、Objectは「状態(属性や値)と定義された振る舞い(メソッド)を持つ全てのデータ。もしくは全ての新スタイルクラスの究極の基底クラスのこと」と説明されています。
まとめると、PythonにおけるObjectは二重の意味を持つ言葉ということがわかります。
・属性とメソッドを持つデータ
・どんなクラスもobjectを継承する(究極の基底クラス)
さて、ここからはPythonにおけるデータの振る舞いについて。まずは、Objectが「等しい」ということがどういうことなのかを考えてみます。
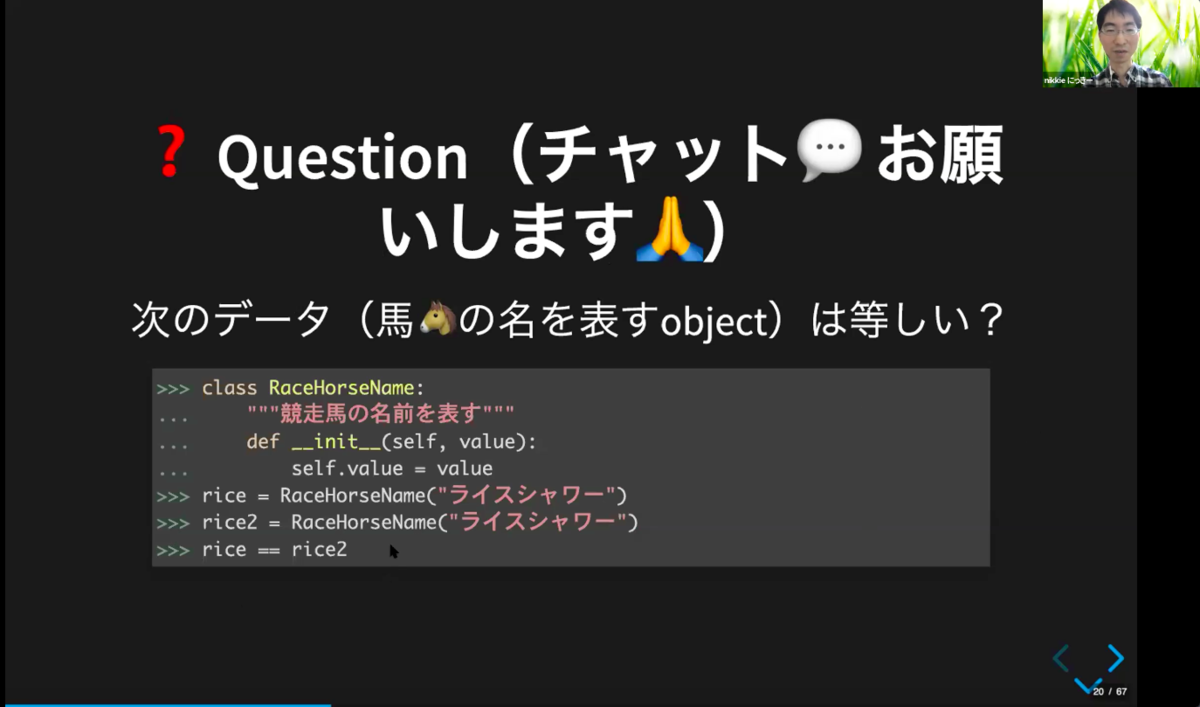
皆さんは上記の馬の名前を表すObjectの比較がTrueなのかFalseなのかわかりますか?
答えは、False。value属性の値はそれぞれ等しいですが、Objectとして同一ではないのでFalseとなります。

もう少し細くみていきます。この「==」が何をやっているかというと、「x.__eq__(y)」というメソッドを呼び出しています。
このメソッドは先ほどのクラス(RaceHorseName)には実装していないメソッドですが、究極の基底クラスobjectが__eq__を持っています。ドキュメントによると「True if x is y else NotImplemented」、x is yがtrueなのであればtrueを返す、そうでなければNotImplementedを返すと説明されています。
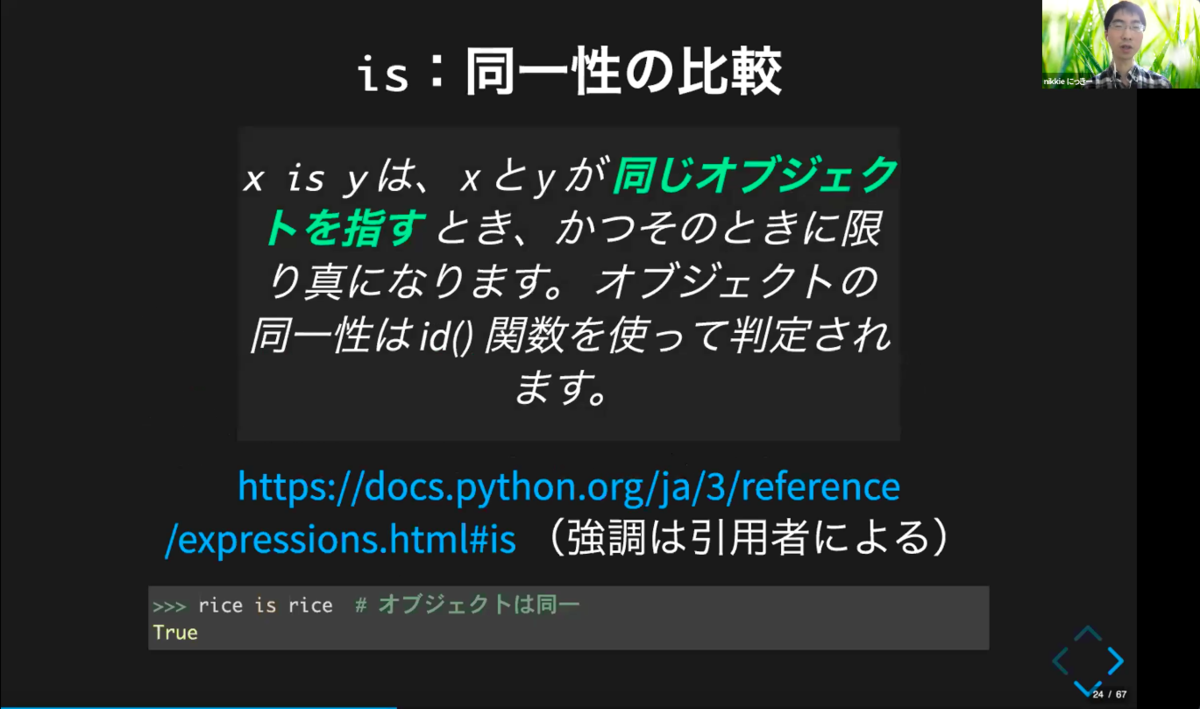
「is」とは同一性の比較。「x is yはxとyが同じオブジェクトを指すとき、かつその時に限り真になります。オブジェクトの同一性はid()関数を使って判断されます。」と説明されています。
等しくなかった理由をまとめると下記の通りです。
・rice == rice2は、オブジェクトの同一性を比較する結果になった
・rice と rice2は別々のオブジェクトを指すので、False
・(組み込み関数idで、別々のオブジェクトを指していることが確認できます)
一方で、「等しい」を作ることも可能です。value属性の値が等しい時、データ(Object)は等しくしたい(ライスシャワーはライスシャワー)場合は、「__eq__」メソッドをRaceHorseNameクラスで実装する、つまりobjectの「__eq__」をオーバーライドすることで「等しい」を作ることができます。
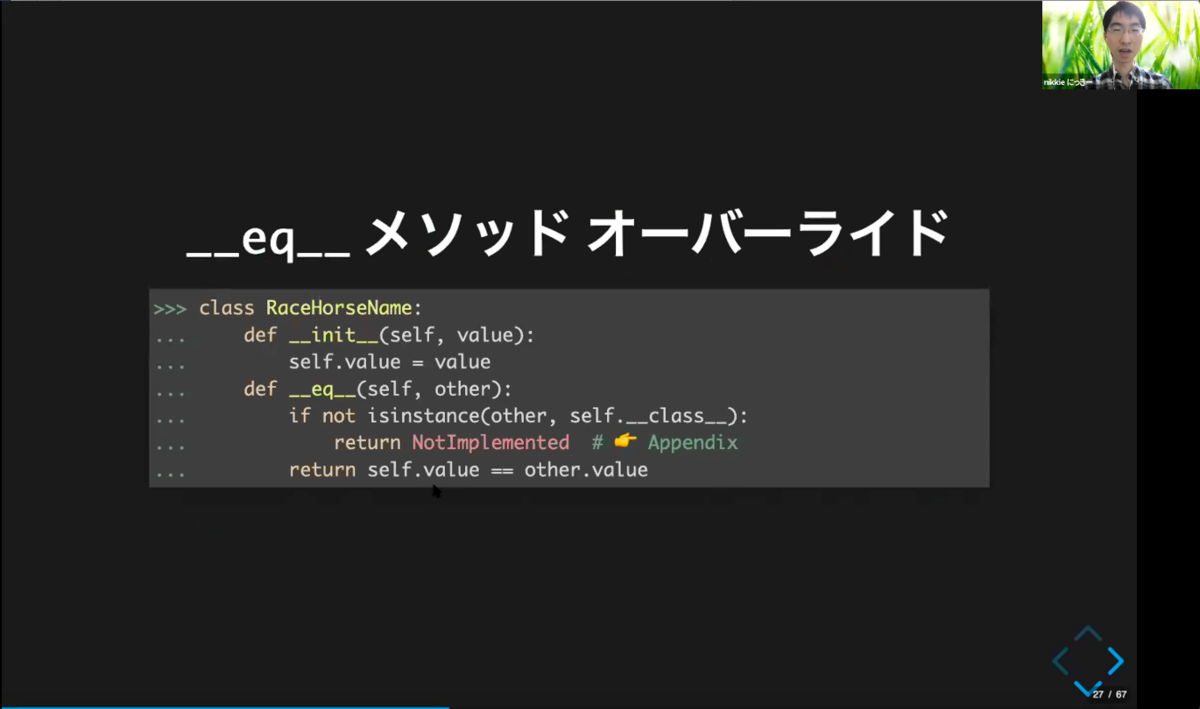
コード例は上記図の通り。==でvalueを比較しています。
さらに、「dataclass」を使うともっと簡単に「等しい」を作ることができます。
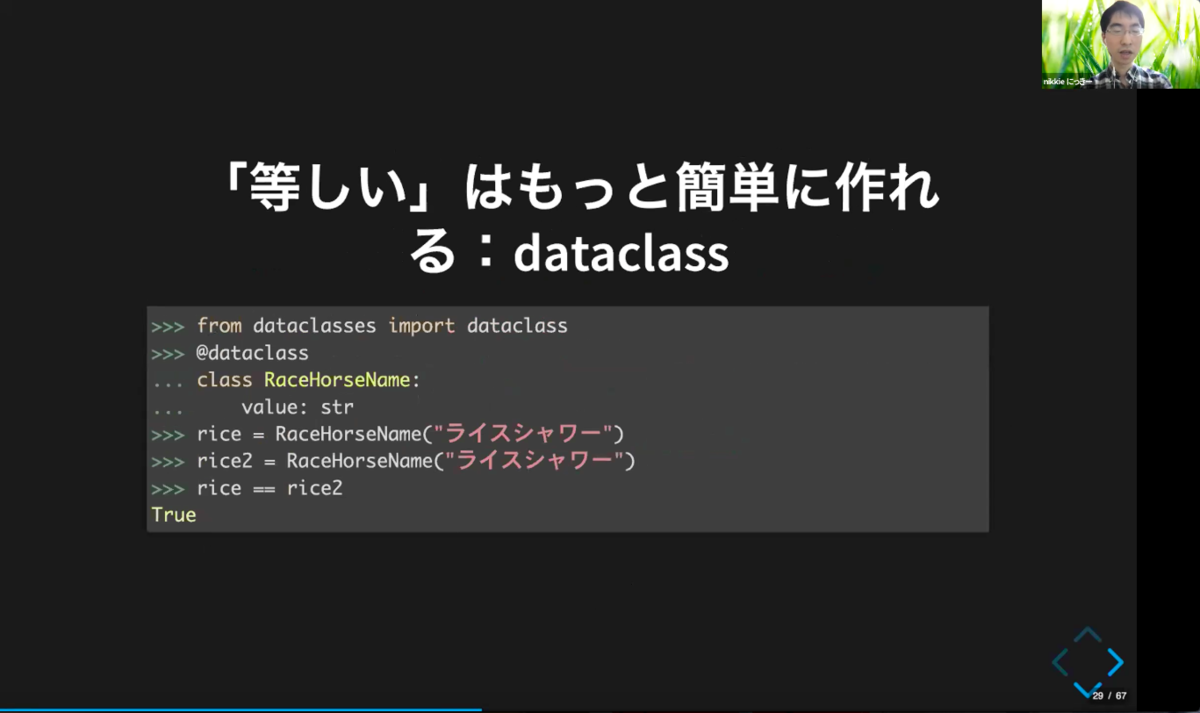
from dataclassesからimportし、@dataclassの形でclassにつけると、==での比較がTrueに!
@dataclasses.dataclassは、クラスにつけるデコレータで、これをつけるとデータに「__eq__」メソッドが勝手に作られ、objcetの「__eq__」をオーバーライドしてくれるそうです。
ちなみに、@dataclasses.dataclassのeq引数もあり、こちらは「eq:(デフォルトの)真の場合、__eq__()メソッドが生成されます。このメソッドはクラスの比較を、そのクラスのフィールドからなるタプルを比較するように行われます。比較する2つのインスタンスのクラスは同一でなければなりません。」と説明されています。
「等しい」の作り方をまとめると、
・クラスに __eq__ メソッドを実装して、object の __eq__ をオーバーライドすればいい
・@dataclasses.dataclass でクラスをデコレートすると __eq__ メソッドが作られて、少ない記述で済む
特殊メソッドとは
先ほど示した「__eq__」などのメソッドを特殊メソッドと呼びます。これらは、究極の基底クラスobjectで定義されており、オーバーライドすることでデータの振る舞いをカスタマイズすることができます。また、これらはマジックメソッド、ダンダーメソッドとも呼ばれます。
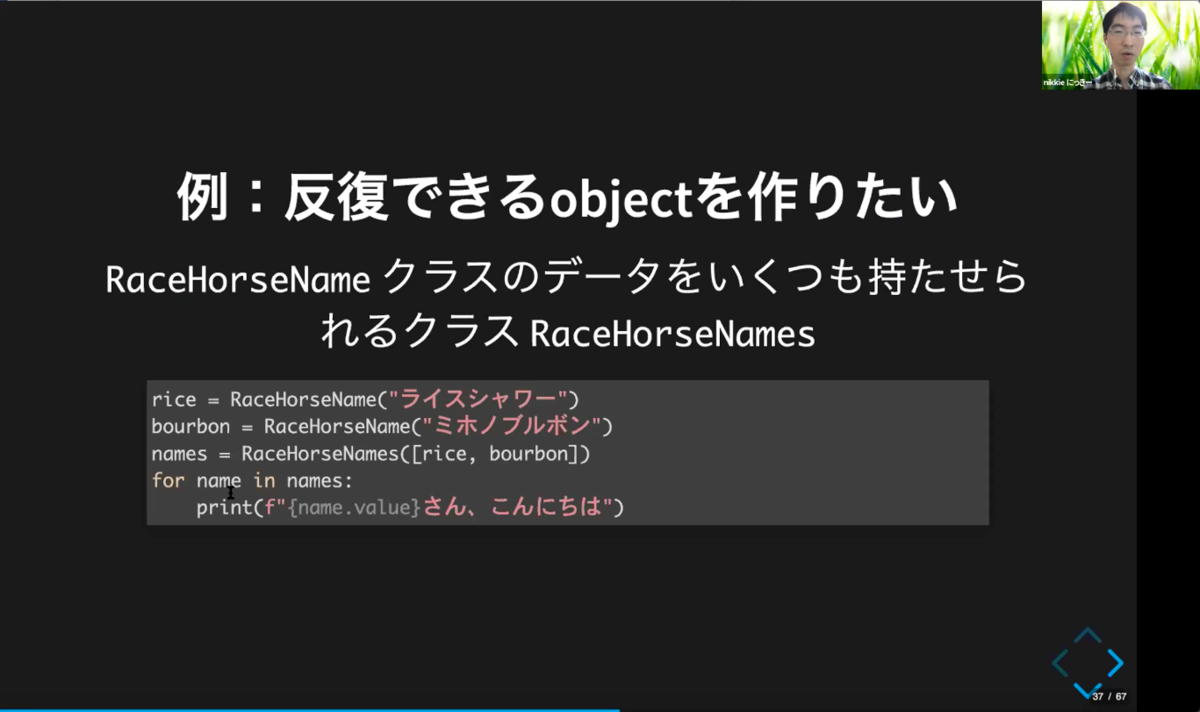
例えば、反復できるObjectは上記のように使えます。これを作りたい場合は下記のように作成します。これはSequenceというクラスを継承しており、特殊メソッドをオーバーライドして作成しています。for文で繰り返したいだけであれば、Iterableになれば良いので、他の特殊メソッドをオーバーライドしても作れます。
Sequenceの例はリストやタプル。整数インデクスによる効率的な要素アクセスを「__getitem__()」特殊メソッドを通じてサポートし、長さを返す「__len__()」メソッドを定義したIterableです。
反復できるObjectは、下記の方法で作成することができます。
・以下の特殊メソッドを実装
__len__
__getitem__
「__len__」とは、Objectの長さを0以上の整数で返すメソッド。「__getitem__」はself[key]の値評価(evaluation)を実現されるために呼び出されるメソッド。Sequenceの場合、キーとして整数とスライスオブジェクトを受理しなければならないとされています。
この際、抽象基底クラス(Sequence)を継承することがおすすめ。なぜなら、「collections.abc.Sequence」を継承することで「__len__」と「__getitem__」の実装が強制されるからなのだとか。nikkieさんは、実装する特殊メソッドを覚えておくより、継承する抽象基底クラスを覚えておく方が、覚える量が少ないと感じているため、オススメしたいそうです。
まとめ
・PythonのObjectはデータであり、究極の基底クラス
・object が持つ特殊メソッドをオーバーライド して、データの振る舞いをカスタマイズ
- @dataclass で特殊メソッド作成
- 抽象基底クラスを継承して特殊メソッド実装
LT王子と呼ばれる理由がわかるような非常にわかりやすいご説明でした!nikkieさんありがとうございます◎
当日の資料はこちら
ftnext.github.io
※nikkieさんのレポートはnikkieさん確認の上で掲載しています。技術的な誤りに気づかれた場合は、nikkieさん (https://twitter.com/ftnext) まで連絡ください◎
Pythonのトレンド情報・この先Pythonに取り組んでいく際に抑えておきたいポイント
現在、東京大学先端科学技術研究センターに勤務されている辻さん。月に1度開催している「みんなのPython勉強会」は2021年5月に6周年を迎えるそう!
早速Pythonの進化の歴史からPythonのトレンド情報を伺っていきます◎
Pythonのトレンド情報
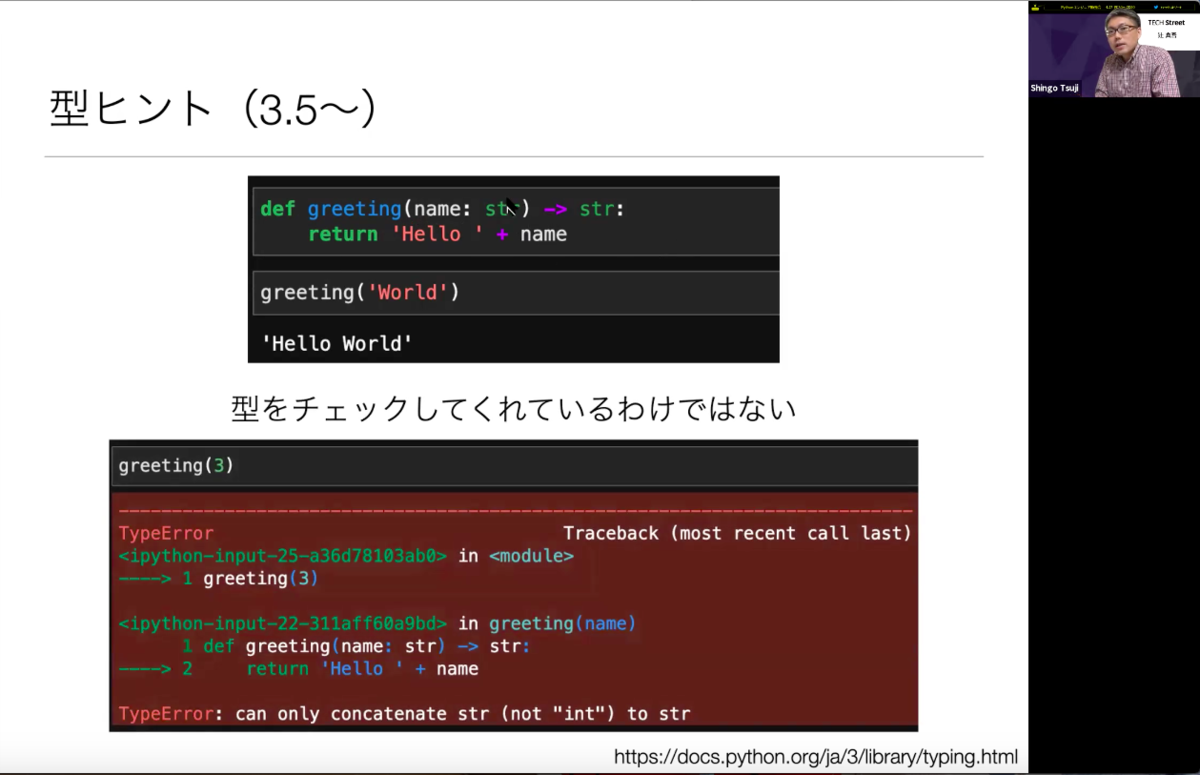
まずは、3.5から導入された型ヒントについて。Pythonは動的型付け言語なので、引数や戻り値は型を書かなくて良いのですが、型を書く「型ヒント」といったものがあります。「型ヒント」については、「みんなのPython勉強会」の第67回で詳しくご説明されているようなので、興味のある方はぜひチェックして見てください。
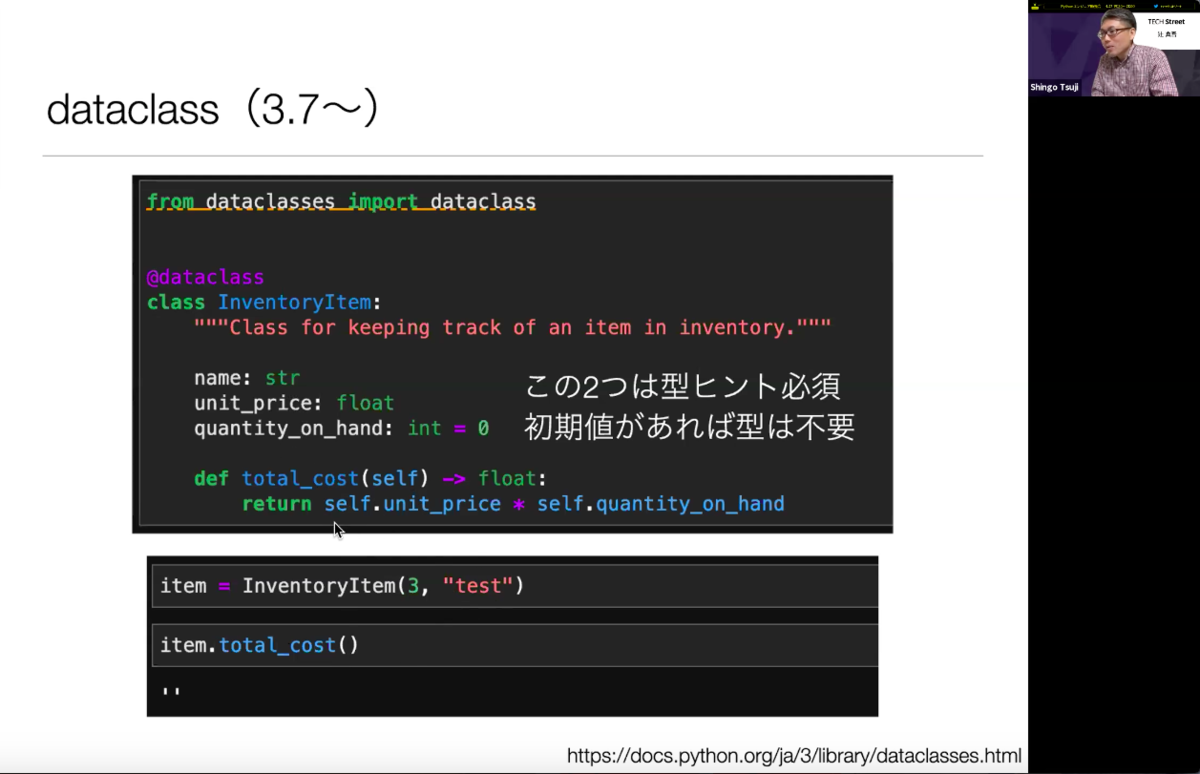
次は3.7から導入された、dataclassについて。こちらは、初期化メソッドを自動生成してくれる非常に便利な機能です。dataclassを書くときは型を書かなければなりませんが、「name: str 」「unit_price: float」は省略することが出来ません。ただ、型ヒントを書いても標準のPythonは何かをチェックしてくれているわけではないので、注意が必要。
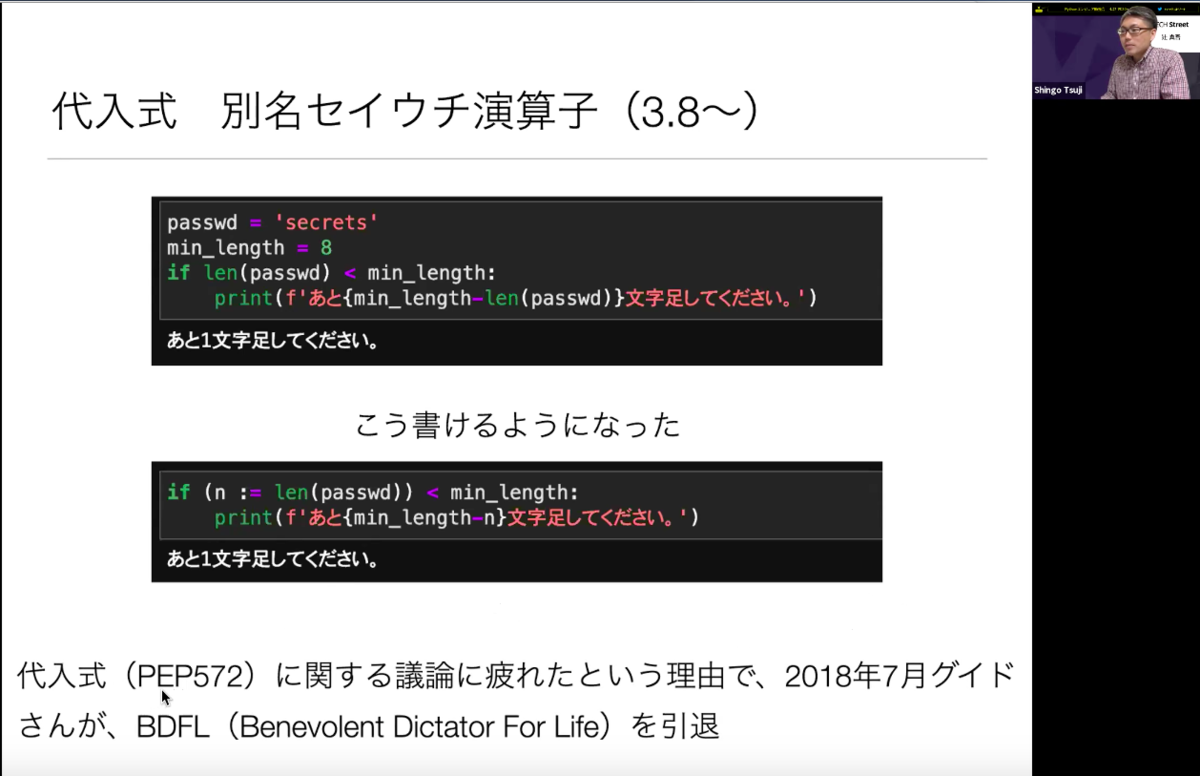
続いて3.8から導入された代入式。別名セイウチ演算式。(:= ←これがセイウチのようだからセイウチ演算式と呼ばれているのだとか)代入式PEP572に関する議論に疲れたという理由で、2018年7月にGuidoさんBDFL(Benevolent Dictator For Life)を引退するという曰く付きの機能なのです…!
このように、Pythonは着々と進化を重ねてきたのですね。
アメリカのAnaconda社が配布するPython「Anaconda」についても、トレンドの1つとしてご紹介します。こちらは、普通のPythonにAnaconda社が独自に作っているcondaというコマンドがついています。多くの外部ライブラリを同梱しており、データ解析機能が充実しているため、いちいちインストールをしないで済み、非常に便利。このcondaというコマンドがpipとvenvの機能を持ち合わせていたため非常に便利だったのですが、2020年9月に規約が変更され、完全無料では使えなくなってしまったそうです。ただし、一部条件があるようなので、気になる方はぜひ詳細解説ページをご確認ください。
このAnacondaがなぜ流行ったかというと、昔は、外部ライブラリをインストールするときに失敗するようなことがあったためなのだそうです。
ただし最近は下記のような環境設定で対応できるようになってきました。
・環境に依存したバイナリを含むwheel形式の普及によってpipのインストールで困ることがなくなってきた
・標準のPythonだけでOK
・仮想環境をvenvで作ってpipライブラリを管理する
・Windowsではランチャーのpyコマンドが便利
この先Pythonに取り組んでいく際に抑えておきたいポイント
この先のPythonにおいては、下記のようなポイントに注目しているのだとか。
・型ヒントの普及
・テスト駆動型開発
・Rust等比較的に新しい他の言語との連携
・人気に陰りが出るのはいつか
・3.9のgraphlib.TopologicalSorter
また、上記以外の注目すべきポイントとしてデータサイエンスにおけるlow code、 no codeがあげられるそうです。今回ご紹介いただいたのは下記3つのライブラリ。
・pandas-profiling
探索的データ分析(EDA:Exploratory Data Analytsis)の強い味方
・PyCaret
機械学習の自動化
依存するライブラリが多いのでインストールして試す場合は仮想環境がおすすめ
・PlotlyとDash
インタラクティブな可視化とWebアプリ開発
pandas-profiling
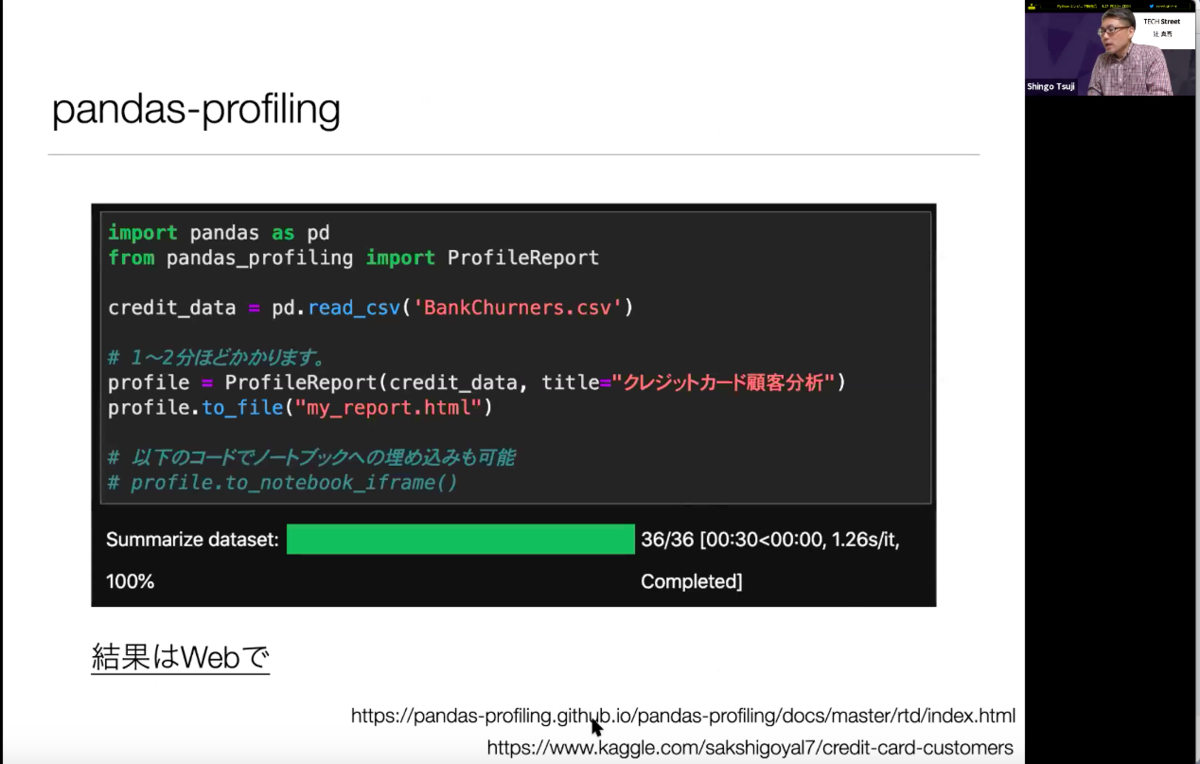
こちらはpandas-profilingでレポートを出力するためのコード。使っているデータはKaggleのデータとなります。
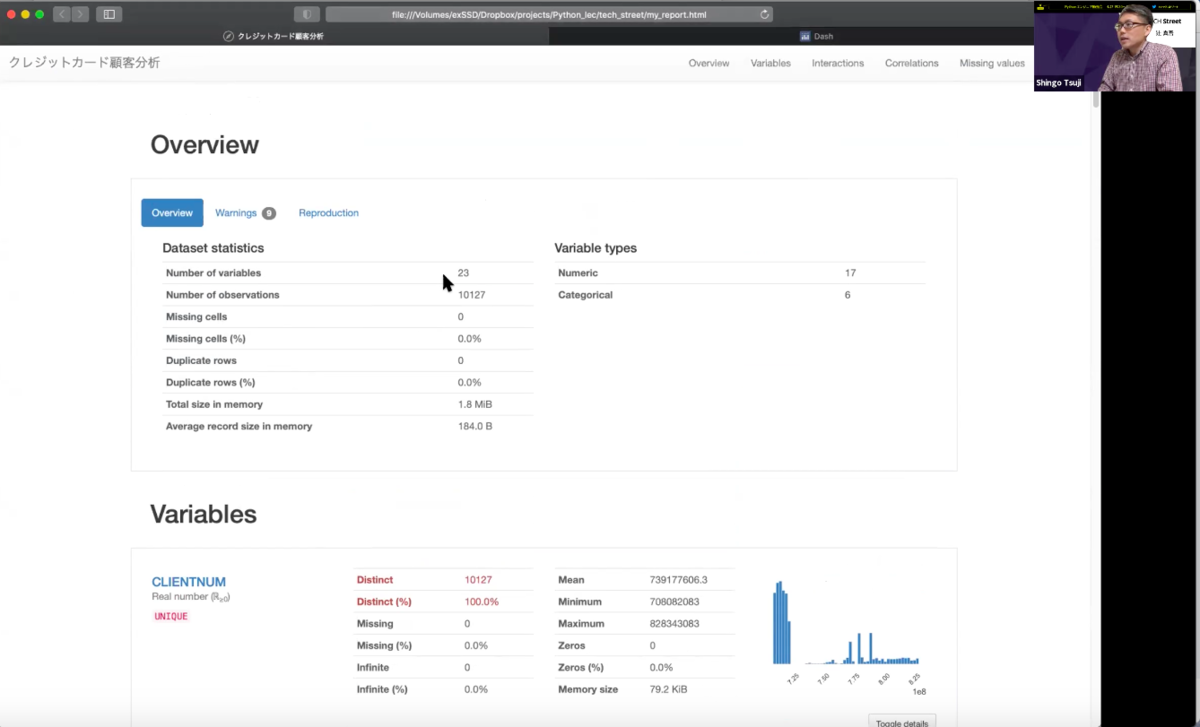
このコードの結果が上記図のようなアウトプットになります。変数ごとにカテゴリカルデータをレポートしてくれ、変数同士の相関もレポート出力して可視化することができます。
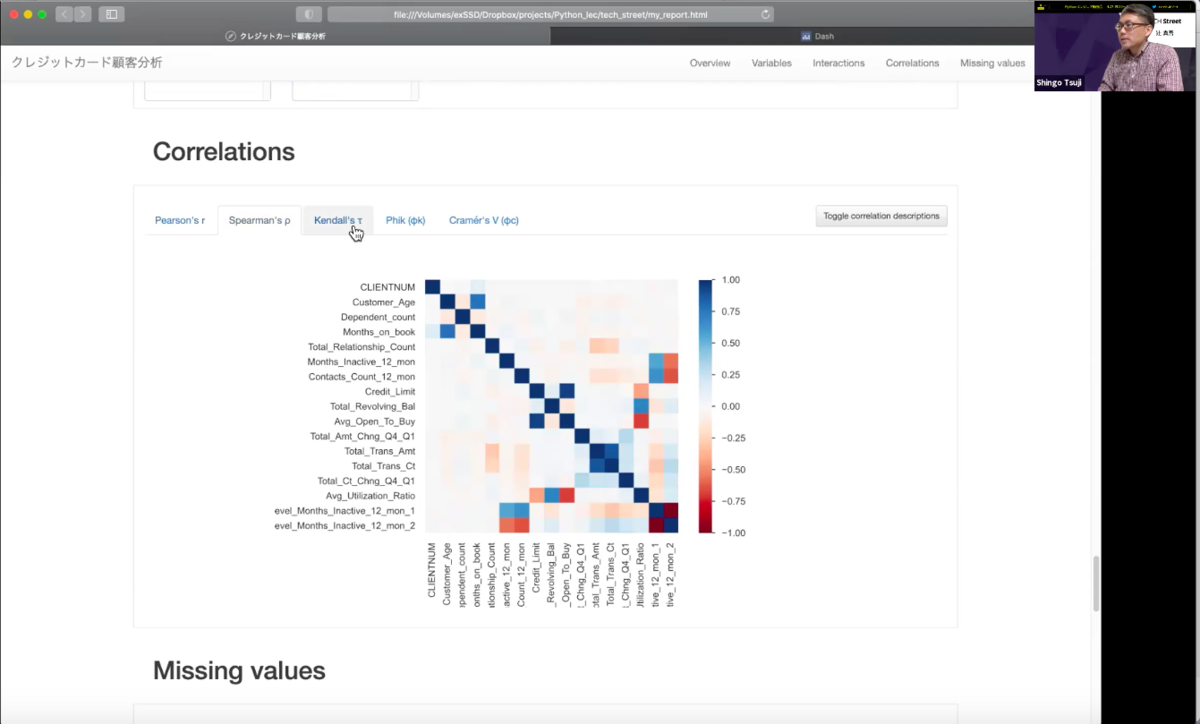
また、変数の相関を数値化したものをヒートマップで表してくれる機能も。連続値とカテゴリー値を両方扱える変数の相関図も実装されています。先ほどのコードだけでこれだけのデータを出せるので非常に便利。ただし、データが巨大すぎると結果が戻ってこなかったりすることもあるそうなので、注意が必要です。
PyCaret
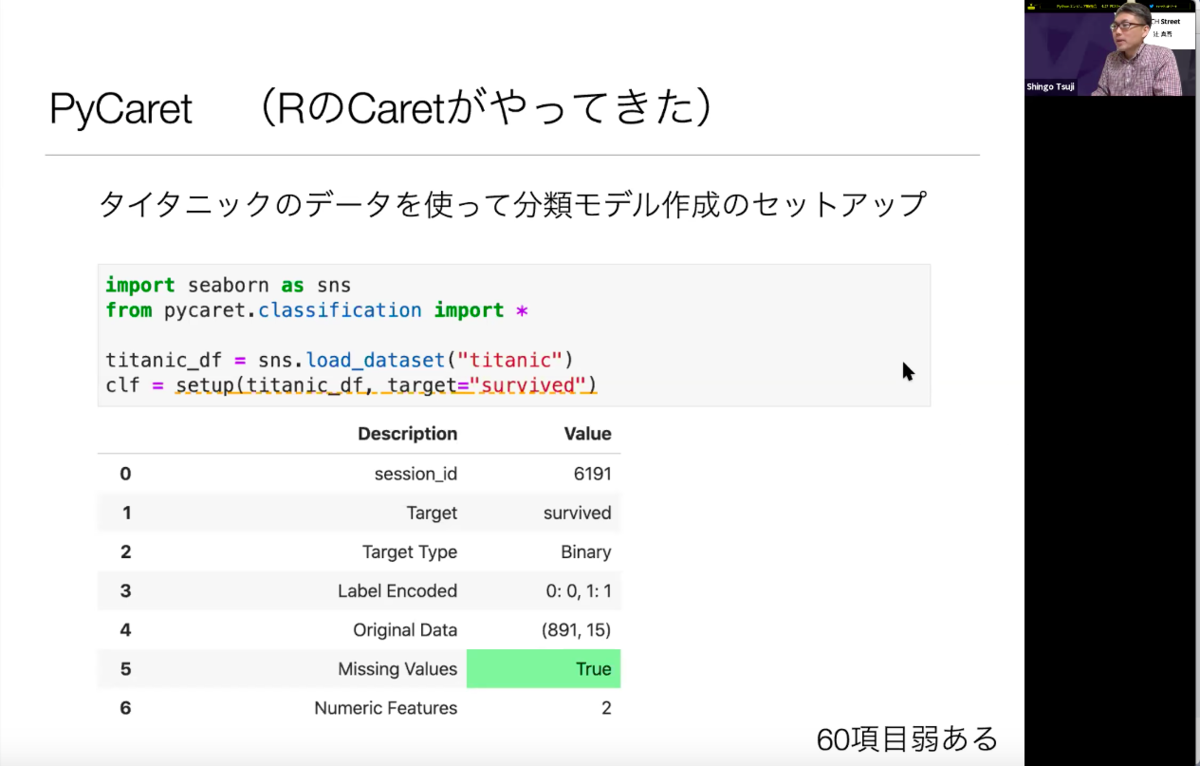
Pycaretは機械学習の自動化を可能とします。こちらは60項目ほどあり、非常に細かく設定できますが、設定に応じて12個のモデルを自動で生成することができるそうです。
PlotlyとDash
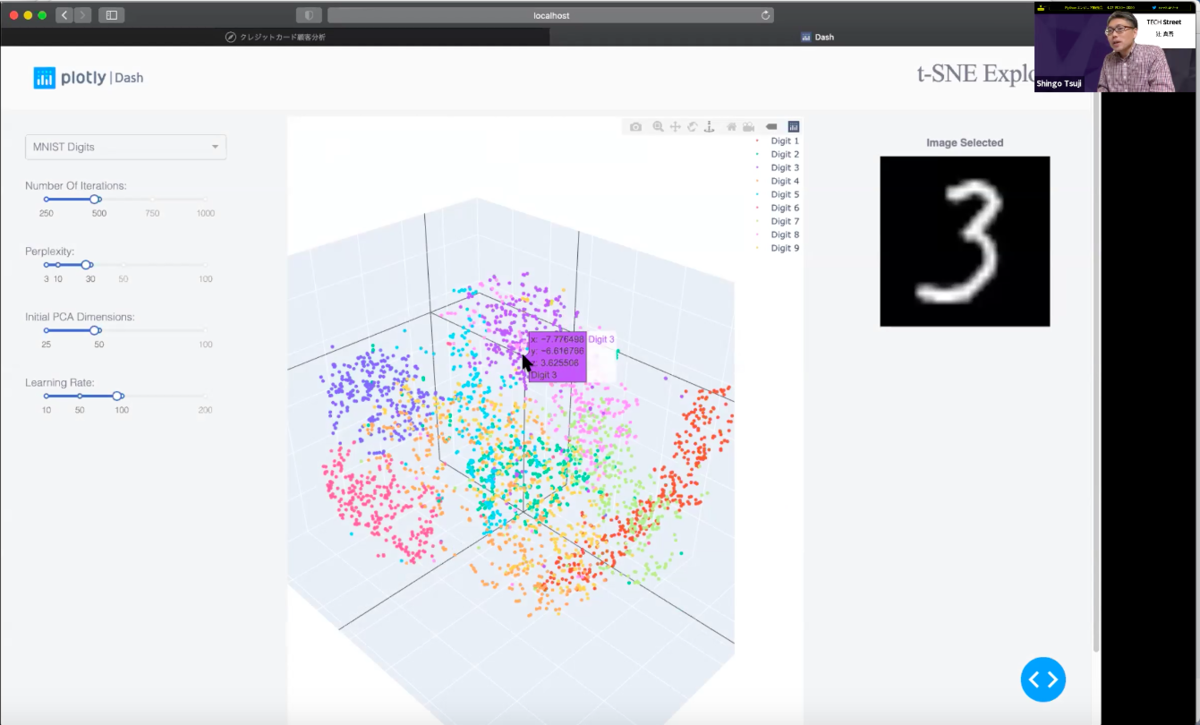
こちらは手書きの数字データをt-SNEで3次元に次元削減をしてプロットしたもの。中身を見ると600行ほどあるのですが、このようなアプリをスクラッチで作ろうと思ったら通常は600行では済まないので非常に便利。
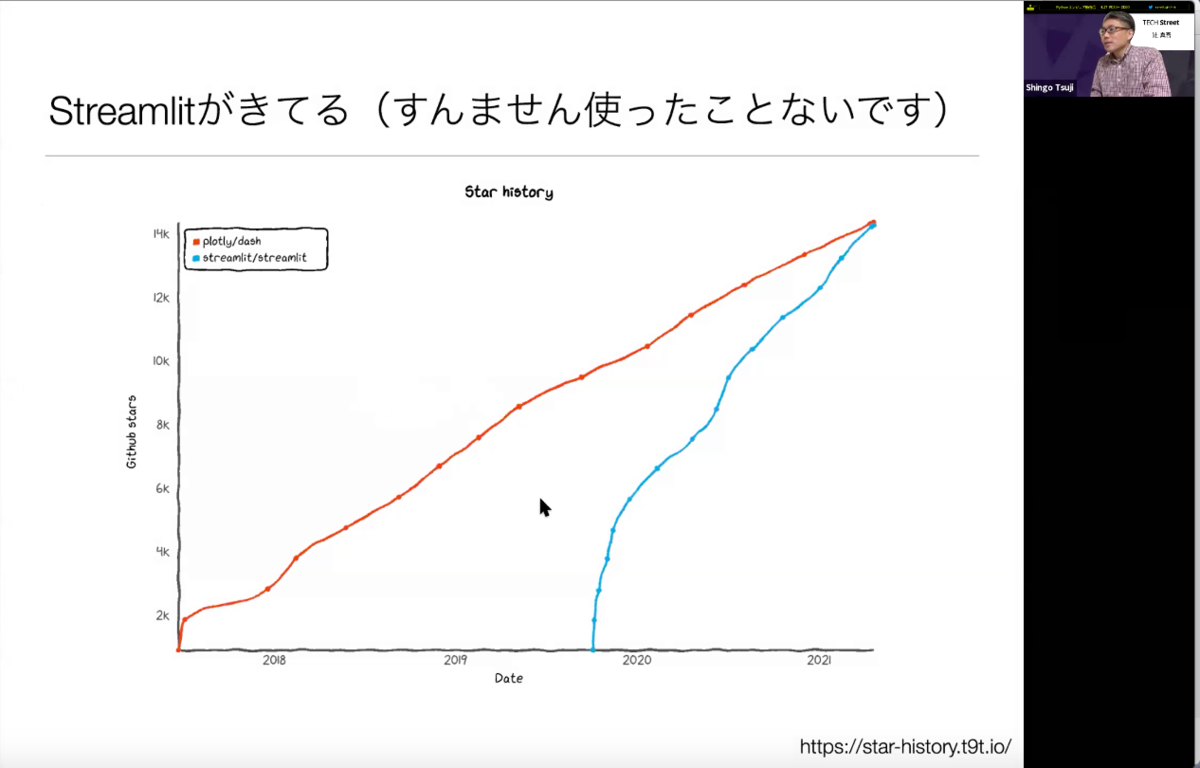
上記図の赤線がPlotlyとDash、青線がStreamlitですが現在はStreamlitが急激に伸び始めているのそうです…!おそらく、最初に手をつけるのにはDashよりStreamlitの方が、敷居が低いのでは、と辻さんは語ります。何れにしても、low code、no codeの流れがデータサイエンスに到来していることは間違いありませんので、今後も注目が必要です。
当日の資料はこちら
http://www.tsjshg.info/20210427_TSUJI_TECHStreet_.pdf
まとめ
たくさんのご質問ありがとうございました!それぞれの立場から違う目線で眺めたPython事情、非常に興味深かったですね!ご登壇者の辻さんやnikkieさんの参加されている勉強会なども多く主催されているようですので、ぜひ今回のイベントを機に、エンジニアの皆様が繋がっていけたら嬉しいと思います◎
次のページでは当日回答しきれなかったご質問への回答も含めて紹介いたします!
参加者からの質問
“(Q)Pythonを社内新人学習対象にしたいのですが、学ぶ(学ばせる)際のポイントってあればお聞きしてみたいです。書籍?web?なにから入れば良いでしょう?”
久保田さん:Udemyなどからはじめてみるのが良いかと思います。書籍は結構重たいと思うので、動画から入って、その知識を補完する形で書籍というのが入りやすいかと思います。
nikkieさん:その人が本の方が好きか、動画の方が好きかという好みもあるかと思いますが、体験してみるという点では、今だとGoogle ColaboratoryなどでPythonの環境を作ることもできるのでその辺りで試して見るのが楽しいのではないかと思います。python.jpと調べていただけると、無料のチュートリアルも多くあります。
辻さん:私の本を読んでいただけると嬉しいですが、最近は本が多くあるのでぜひ本屋さんで自分に合う本を見つけてください。最近見つけたサイトだと、(https://mikiokubo.github.io/analytics/ )こちらがなかなかの情報量だと思います。こちらのサイトでは、Pythonの基礎を学ぶための練習問題がいくつかあり、こういう問題をやって見るのがいいと思います。書けるようになるには書くしかないかと思います。
“(Q)pandas-profiling、便利だと感じたのですが、すごく重そうな印象を受けました。どのくらいのデータだとどのくらいの時間で返ってくる等わかりましたら、教えていただきたいです”
辻さん:例えば、タイタニック号のデータをpandas-profilingに投げると暴走して1時間くらい返ってこないなんてこともありましたね。まだまだ開発の余地があると思います。
“(Q)インデント深さで制御構造を示す言語仕様、みなさんは好き?嫌い?”
久保田さん:そこまで意識したことはないですが、仕様的には好きではないですね。Pythonがその形になっているから従っているという状況ですね。
nikkieさん:私は大好きです。慣れちゃいましたね。
辻さん:私も大好きです。他の言語でも必ずインデントの深さを合わせるようにしていたので、すごく好きな言語仕様の一つです。
“(Q)まだ触ったことがないのですが、バージョンの意識ってどれくらい必要なのですか??アドバイスお願いします!”
久保田さん:学習段階ではそこまで意識する必要はないですが、実際のアプリケーション開発の場合は、まずはメジャーバージョンの方が意識した方がいいと思います。マイナーバージョンはあまり意識しなくても問題はないのですが、私の場合は動かなくなってしまったこともあったので、意識するようにしています。
nikkieさん:私は新しい方が好きなので、意識的にあげるようにしています。バージョンが上がるほど表現力が増えるのがすきですね。
辻さん:結構バージョンは重要ですね。個人的には、最新より一つ前くらいがいいのではないかなと思います。
“(Q)Pythonのここ1年で1番のNewsって何でしょうか?”
久保田さん:3.9が出たのは結構大きいなと思っています。ここからどうなっていくのかを追っていく必要があるなと思っています。
nikkieさん:Python3.9から組み込みのlistやdict、tupleなどがジェネリック型になったのですよね。それまでtypingでやってきたもの(List, Dict)を、型ヒントが定着してきたからlistやdictに変えようという動きになったので大きい動きかなと思っています。
辻さん:Python Software Foundation(PSF)が、財政難に陥っております。理由は、コロナ禍において毎年開催していたイベントが開催できなくなったことなどがあげられるようです。PSFでは常時寄付を受け付けているので、ぜひ寄付して助けてもらえると嬉しいです!
“(Q)Python開発で一番困る事って何でしょうか?”
久保田さん:アプリケーション開発においては、まだベストプラクティスが固まっているわけではないので、その場その場で技術選定を考える必要があるのが大変だと思います。
nikkieさん:向かないアプリもあると聞いています。大量のリクエストを捌く必要があるWebアプリケーションは向いていないそうですね。
辻さん:あまり困ることはないですが、強いていうなら様々なライブラリが次から次へと出てきたり、開発が早かったりするので、この前まで使っていたメソッドが急に使えなくなるということがあり、ついていくのが大変ということはありますかね。
“(Q)エクセルやアクセスではハンドリングがしんどいデータを効率的に処理するツールとしてPythonを使うのってありですか?”
辻さん:これは、Pythonを利用し始める絶好のチャンスです。何かやりたいことがないとプログラミングを続ける動機にならないので、ぜひハンドリングがしんどいと思うところをPythonで解決する方法を考えるのがよいと思います。エクセルは見た目がわかりやすい利点がありますが、繰り返しや込み入った作業はPythonでかなりのことが楽になると思います。
nikkieさん:Pythonを使うのはありだと思います。
アクセスは全然わからないのですが、エクセルでハンドリングがしんどい=データ量が多いということかなと思いました(例:百万行ほどあるCSVで、エクセルにインポートするととても重くなる)。例の場合だとPythonのジェネレータを使うとメモリに優しくデータを処理できてオススメですよ。
“(Q)現在統計やデータサイエンスでNumpyやPandasはよく出てきますが、登壇者の皆様は実務で使用する機会はありますか?”
辻さん:実務で日常的に使っています。教えたりすることも多いですが、自分で使っていないとやっぱり教えられないなと思います。また、Numpyもpandasも巨大なライブラリなので、自分が結構使えると思っていても、知り合いのコードやドキュメントをみて「なにー、そんな機能もあるのかー」と驚くことはいまでも結構あります。
nikkieさん:NumPyは実務でよく使います。PyTorchのTensorからnumpy.ndarrayに変換するなど。私はNumPy力をもっと付けたいと思っています。
pandasは表形式のデータを扱うのに便利だと思います。ですが、私の働いているチームでは使いません。私や同僚のデータサイエンティストは機械学習のモデルをアプリケーションに組み込むところまで担当しており、アプリへの組み込みまで考えるとpandasは適さないと考えているためです(代わりにNumPyで扱っています)。また、pandasが威力を発揮する表データではなく、自然言語のテキストを扱っているというのもあります。pandasでテキストデータを扱うのに特化したtextheroライブラリもあるので参考にしてみてください。
“(Q)よくプログラミング(仕事)って、理数系じゃなくても文系が逆に強かったりもする。なんて聞きますが、Pythonは数学に強い人が強い感じなのでしょうか?”
辻さん:それはないと思います。グイドさんが数学すごいできるという話を冒頭にしてしまったので、混乱させてしまったらすみません。プログラミングができるできないは未だに私のなかでも謎で、学部時代の同期(理系の学科です)でも全然プログラミングできない友人もいました。興味のあるなしは関係しそうですが、それ以外にもなにかあるのではないか?といまも探し続けています。
nikkieさん:データ分析・機械学習の分野は、たしかに数学が強い人が多いかもしれません。ですが、数学が強くなくても、良いソフトウェアが作れれば、機械学習のモデルの組み込みで価値を発揮できます。そして、良いソフトウェアを作れるようになるためには、文系・理数系というスタートラインはあまり関係なく、先人の知恵を一歩一歩自分のものにしていけるかだと思っています。
“(Q)(10年ぶりのPython)こんなおっさんでも今からついていけますかね?(還暦近いです)”
辻さん:Pythonは、CやC++、Javaと比べてもプログラミング言語としてわかりやすくなっているので大丈夫です。昔はプログラマ32歳定年説(32が2の5乗だからこの数字が好まれただけ?)なんてのもありましたが、エラーが起こったときの対処のしやすさなどはCとは比べものにならないので、わたしもずっとプログラミングは続けたいと思っています。(どこかで大金持ちになったら、引退するかもしれませんが・・・)
nikkieさん:ついていけると思います!
10年前と比べるとPython2系から3系への変化でしょうか。変化した点は大量にありますが、Pythonの本質は変わっていないそうです。
また、トミ爺さんなど、還暦を超えてからアプリ開発を始めて活躍されている方もいらっしゃるので、ロールモデルとして参考になるのではないでしょうか。
“(Q)Pythonのコードを書くうえで、愛用しているエディタはなんですか?VSCode, PyCharmなどですか?そのエディタを愛用している理由も聞きたいです。”
辻さん:エディタはVSCodeを使っています。この25年のエディタ遍歴としては、Emacs→秀丸→Emacs→ちょっとだけSublimeときて、数年前からVSCodeです。設定ファイルがJSON形式なのでわかりやすいのと、Pythonの仮想環境の切り替えなどにも対応しているので気に入っています。最近波に乗っているエディタなので、いろいろな機能の開発が速い(多くの人が開発に参加している)のも魅力です。PyCharmは話題ですが、使ったことないです。
nikkieさん:VS Codeです(Pythonに限らず使います)。軽いのがいいなと思います。またExtensionが充実しているのも魅力です。Pythonを書く際はファイルの保存をトリガーにflake8でリントしたり、blackでformatしたりできるように設定すると気持ちよく書けてオススメです(settings.json)
“(Q)Pythonの特性上実行速度が他の言語に比べて遅いと思いますが,早くする書き方などありますでしょうか?”
辻さん:重い仕事をさせるときは、気楽に書いて速度はあきらめ、コーヒーをいれにいくことにしています。いわゆるJITコンパイラをPythonに導入する試みはいろいろあって、たとえばNumbaなどが有名ですが、基本マニア向けだと思います。ただ、pandasのDataFrameではfor文は使わないとか、ちょっと気を付けるだけで速度が変わるtipsもあります。
nikkieさん:Pythonのfor文は遅いので内包表記を使うのがオススメされますね。実行速度についてはPythonで競技プログラミングについて調べれば情報が見つかると思います。PyCon JP 2020の発表にはPyPyというものを使って実行を高速化するというtipsがありました
“(Q)WindowsアプリをPython使って開発してますか? そもそも、Windowsアプリ開発に向いているのでしょうか?”
辻さん:WindowsネイティブのGUIアプリということですよね。すみません、私はこの分野の開発経験がほとんどないです。20年以上前に、Delphiという開発ツールを触ったことがある程度です。Windowsアプリを作る場合は、やはりマイクロソフトが提供している開発環境を使うのが良いと思います。今だと、C#かVBで.netプラットフォームで作りますよね。PythonでもWindowsのGUIアプリを作れますが、やはり適材適所な言語の方が、開発の速度や保守性という面で良いと思います。贔屓目に見ても、PythonはWindowsアプリ開発に向いている言語とは言えないと思うので、もしできるならスタンドアローンで利用するWebアプリにするというのもありかもしれません。
イベントレポートは以上となります。次回のイベントもお楽しみに!
